 zmx2321
zmx2321http (前端的生命线)
1. 简述
- 前端工程师开发界面
- 需要调用后端接口,提交/获取数据 => 需要用到http协议
- 要求事先掌握好ajax
2. 题目
- http常见状态码有哪些
- http常用的header(响应头、请求头)有哪些
- 什么是Restful API
- 描述一下http的缓存机制(重点)
3. 知识点
3.1. http状态码
- 状态码分类
- 1xx => 服务器收到请求
- 2xx => 请求成功
- 3xx => 重定向
- 4xx => 客户端错误
- 5xx => 服务端错误
- 常见的状态码
- 200 => 成功
- 301 => 永久重定向(配合localtion,浏览器自动处理)
- 浏览器会记住,遇到直接跳转新的地址
- 网站域名到期
- 302 => 临时重定向(配合localtion,浏览器自动处理)
- 浏览器访问一个地址,只有第一次会跳转到新的地址
- 百度知乎邮箱等搜索引擎里面点击链接或者一些短连接,他会先跳转到自己的地址,再跳转到目标网址
- 如果是第一次访问,状态码是302
- 有时候也会有307,307和302差不多
- 第一次访问之后,浏览器有了缓存,再访问,状态码是200
- 如果是短连接,他会先跳转到长连接
- 如果是第一次访问,状态码是302
- 304 => 资源未被修改 - 重点
- 资源如果已经请求过了,服务端有可能会返回一个304,表示已经被存储到本地缓存
- 404 => 资源未找到
- 403 => 没有权限
- 比如登陆
- 500 => 服务器错误 - 最常见
- 504 => 网关超时
- 服务器内部在做一些操作的时候,比如链接其他服务器的时候超时了
- 关于协议和规范
- 就是一个约定
- 要求大家都跟着执行
- 不要违反规定,例如IE浏览器,比如把200当做错误等
3.2. http methods
- 传统的methods
- http刚刚开始的时候(大约十年前)
- 简单的网页功能,就这两个操作
- get => 获取服务器的数据
- post => 向服务器提交数据
- 现在的methods
- get => 获取数据
- post => 新建数据
- patch/put => 更新数据
- delete => 删除数据
- Restful API
- 一种新的API设计方法(早已推广使用) => 常考
- 重点概念
- 传统的API设计:把每个url当作一个功能
- Restful API设计:把每个url当作一个唯一的资源(标识)
- 如何设计成一个资源
- 尽量不用url参数
- 传统的API设计:/api/list?pageIndex=2
- 相当于一个函数(?相当于函数的参数)
- 现在的API设计:/api/list/2
- 就是list第二页资源的标识(或者说id)
- 不会和其他资源冲突,如果说获取详情页,就不叫list,应该是:/api/detail/2
- 即一个完整的地址加上一个唯一标识(id),这就是restful api设计的目的
- 传统的API设计:/api/list?pageIndex=2
- 用method表示操作类型 - 即上面的4个方法
- 传统api设计
- post请求:/api/create-blog => 创建博客
- post请求:/api/update-blog?id=100 => 更新博客
- get请求:/api/get-blog?id=100 => 获取博客
- 相当于把一个api当作一个功能进行设计
- Restful API设计
- post请求:/api/blog => 创建博客
- 表示整个blog资源的标识
- patch请求:/api/blog/100 => 更新博客
- id为100的blog的标识
- get请求:/api/blog/100 => 获取博客
- id为100的blog的标识
- 用method标识操作类型
- post请求:/api/blog => 创建博客
- 传统api设计
- 尽量不用url参数
3.3. http常用的header
- 简述
- 常见的Request Headers => 请求头
- 请求的时候,客户端往服务端发送的Headers
- 常见的Response Headers => 响应头
- 服务端向客户端返回的Headers
- headers在http请求中是一件非常重要的事情
- 常见的Request Headers => 请求头
- 流程
- 我们访问一个url地址实际上就是发送请求
- 我们发送请求实际上要做以下步骤
- 使用某个方法(get、post)去发送一个url
- 我们发送的请求还包括request headers
- 服务端接收到请求会进行返回
- 服务端不止返回结果(json、页面、图片等)
- 服务端还会返回response headers
- 常见的Request Headers(请求头)
- 客户端向服务端发请求
- Accept => 浏览器可接收的数据格式
- text/html、application/json等
- Accept-Encoding => 浏览器可接收的压缩算法,如gzip
- 我们可以根据gzip算法把资源进行压缩(100kb大概可以压缩至30kb左右)
- 浏览器可以识别压缩的内容,也可以解压
- 浏览器告诉服务器,我能接收什么样的压缩算法,服务器就会根据Accept-Encoding的压缩算法进行压缩
- 前后端通用
- 为了保证资源更小,传输地更快一些,前端也可以正常地解压出来
- 表示客户端可以支持什么样的压缩算法
- Accept-Language => 浏览器可接收的语言,如zh-CN
- Connection:keep-alive一次TCP连接重复使用
- 每次请求重新建立TCP连接会很消耗资源
- 现在的浏览器版本基本上都是支持keep-alive的
- 即我们和服务端建立了连接之后,就可以重复地使用这个连接,没必要断开之后重连
- 重复地使用一次连接,把资源一次性请求完成
- cookie
- 同域,每次请求资源的时候都会把cookie带上
- 浏览器自己带的
- Host
- 请求的域名是什么
- User-Agent(简称UA) => 浏览器信息 => 重点
- 能标识你的浏览器信息(类型等)
- 服务端能够接收ua信息,可以判断用户使用的浏览器类型
- Content-type
- 发送数据的格式,如 application/json
- 客户端向服务端请求,要发送一些数据的时候(post),告诉服务端,我们这个数据是什么格式的,一般get请求是没有的,get请求主要是向服务端获取数据
- 常见的Response Headers(响应头)
- Content-type => 返回的数据格式
- 如 application/json
- Content-length 返回数据的大小,多少字节
- Content-Encoding => 返回数据的压缩算法,如gzip
- 客户端告诉服务端支持的压缩算法之后
- 服务端根据压缩算法进行压缩
- 服务端压缩之后会通过Content-Encoding告诉客户端我是用什么算法压缩的
- 浏览器会自动根据这个压缩算法解压
- Set-Cookie
- 服务端改cookie的时候,通过Set-Cookie修改
- Content-type => 返回的数据格式
- 自定义header
- 以上的请求头和响应头是浏览器自带的,或者服务端和浏览器配合加的
- 请求头和响应头实际上可以自定义header
- 自定义请求头的时候,需要前端访问服务的时候加上header
- 自定义响应头的时候,需要服务端向客户端返回之前加上header
- 使用axios做请求,其实我们可以自定义header
- headers:
- 在浏览器上的request headers里面就会多一个请求头,名字和值都可以自己定义,但不要和浏览器自带的键值冲突
- 使用场景
- 有些接口要求在请求头中加一个特定的秘钥,请求才能通过,否则就是非法请求 => 权限验证
- 缓存相关的headers
- Cache-Control
- Expires
- Last-Modified
- IF-Modified-Since
- Etag
- If-None-Match
- 总结
- 如果提问有哪些headers,需要分两步来讲
- 浏览器自带的请求头和响应头
- 缓存的headers
- 如果提问有哪些headers,需要分两步来讲
3.4. http的缓存(重点)
3.4.1. 关于缓存的介绍
- 什么是缓存
- 浏览器访问一个新的网站(本地没有任何信息),服务端会返回所有的资源,并且浏览器或者服务器会将一些不必要重新获取的资源存到缓存区,第二次访问的时候,就不需要全部重新获取一遍资源,有一部分资源会从缓存中获取
- 即我们可以把一些没有必要重新获取的资源不再重新获取,这就是缓存
- 为什么需要缓存
- 为了减少请求的数量和体积,让页面加载和渲染的过程更快一些
- 从键盘输入地址到页面返回,几乎所有操作(cpu计算,页面渲染)都是毫秒级别的,速度非常快,相比较于cup计算而言,唯一慢的就是网络请求
- 如果要做性能优化,让页面显示的更快,我们需要从最大的瓶颈,即网络请求下手
- 我们需要尽量减少网络请求的体积和数量
- 为了减少请求的数量和体积,让页面加载和渲染的过程更快一些
- 哪些资源可以被缓存
- 一些静态资源 => js css img
- webpack打包的时候,我们会加一个hash,hash是通过资源内容来算的
- 打包之后的静态资源文件,加上hash后缀之后,资源是不会被修改的
- 如果内容改了之后,会生成一个新的hash的名称
- html不能被缓存,因为html可能随时会更新
- 业务数据不能被缓存,数据会变
- 一些静态资源 => js css img
3.4.2. http缓存策略(强制缓存+协商缓存)(常考)
3.4.2.1. 强制缓存
- 图示 => 第一次请求(静态资源)
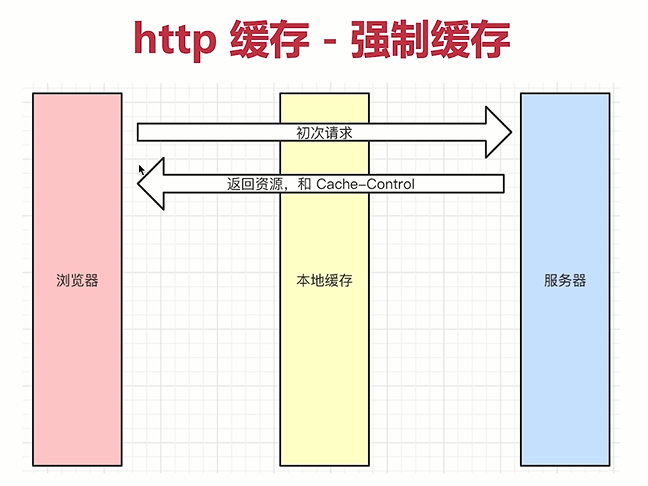
- 根据图示梳理缓存流程
- 浏览器初次请求到服务器
- 会经过本地缓存(设备) => 浏览器的机制
- 浏览器到服务器是通过网络连接起来的
- 服务端会返回资源
- 服务端不止返回资源(结果集),还会返回一个Cache-Control
- Cache-Control是一个响应头(response headers),和缓存相关
- 初次请求之后,如果服务端感觉这个资源可以被缓存,就会加上Cache-Control,如果服务端感觉这个资源不适合被缓存,就不会加上这个Cache-Control
- 一些静态资源(js、css、img)都会被加上Cache-Control
- 如果有Cache-Control,浏览器会将资源缓存下来 => 浏览器的机制
- 浏览器有了资源之后就会开始继续工作
- Cache-Control简介
- 在response headers中
- 服务端控制哪些资源可以加Cache-Control,客户端控制不了
- 控制强制缓存的逻辑
- 强制缓存本质还是服务端控制的
- 例如
- Cache-Control: max-age=31536000 (单位是秒 - 1年)
- 即我们需要将某个资源文件在客户端缓存一年的时间
- max-age表示最大的时间
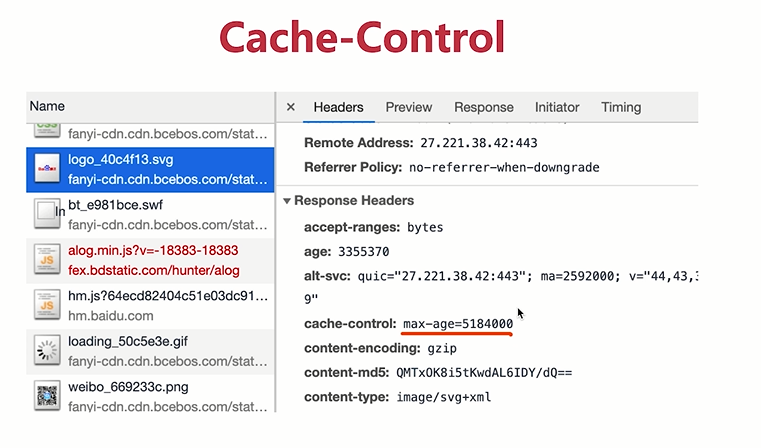
- Cache-Control: max-age=31536000 (单位是秒 - 1年)
- 在response headers中
- 图示 => 第二次请求(静态资源)
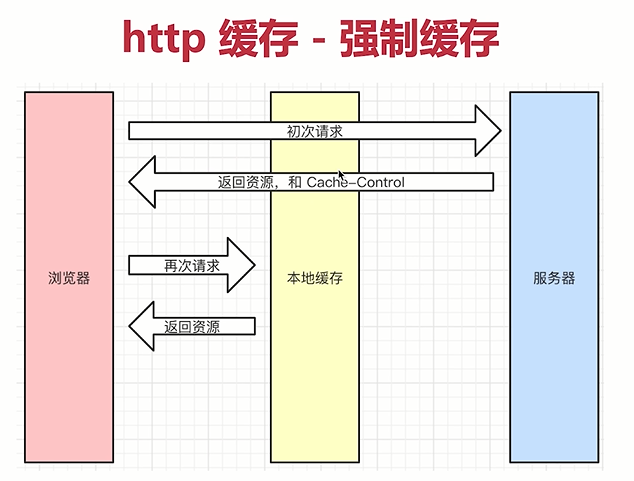
- 根据图示梳理缓存流程
- 初次请求说明见上
- 浏览器再次请求
- 再次请求的时候,他会判断Cache-Control时间是否过期
- 如果时间没有过期,浏览器就会在本地缓存中获取资源
- 即不会去服务端获取资源,直接返回
- 浏览器会根据之前请求的Cache-Control来判断是否可以被缓存,存下来
- 再次请求的时候就会在本地去找,然后去返回
- 没有经过网络
- 浏览器有了资源之后就会开始继续工作
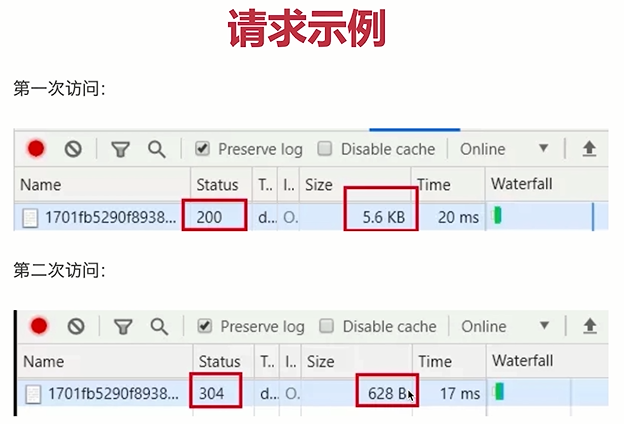
- 从缓存获取资源示例

- 缓存过期了
- 缓存过期,浏览器会再次从服务端请求资源
- 服务端会重新返回资源和Cache-Control
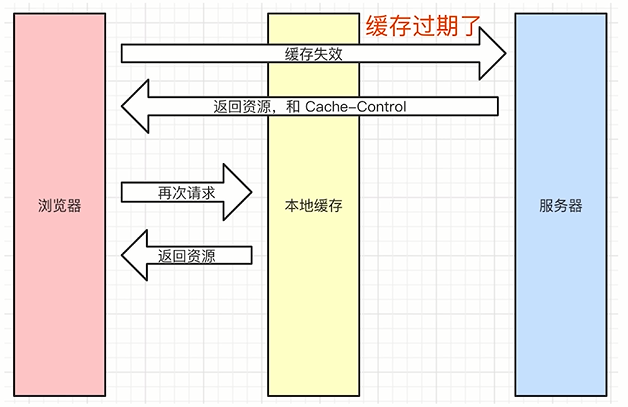
- 服务端会重新返回资源和Cache-Control
- 缓存过期,浏览器会再次从服务端请求资源
- Cache-Control的值介绍
- max-age => 缓存最大过期时间(秒)
- no-cache => 不用强制缓存,正常从服务端请求,服务端怎么做不管
- 不想用缓存,一般用这个
- no-store => 不用强制缓存,也不让服务端做缓存,让服务端直接返回资源
- 不常用
- private => 只能允许最终用户做缓存(设备)
- public => 中间的代理也可以做缓存
- 关于Expires
- 经常会和Cache-Control并列在一起
- 同样在响应头(response headers)中
- 同为控制缓存过期
- 已经被Cache-Control代替
- 现在的浏览器兼容这两种写法,如果同时存在,以Cache-Control为主
3.4.2.2. 协商缓存(对比缓存)
- 简述
- 类似一个商量或者沟通的意思
- 服务端缓存策略
- 服务端来判断这个资源是否可以被缓存
- 不是指这个文件缓存在服务端
- 服务端缓存策略的意思是,我们这个资源到了服务端之后,服务端可以告诉浏览器这个资源没有动,可以直接用本地的缓存就可以了,就不用再让我给你一份了,这次请求就效率很高,体积很小
- 即服务端判断这次请求能不能用缓存的内容
- 服务端判断客户端资源,是否和服务端资源一样
- 如果判断一致就返回304,否则返回200和最新的资源
- 客户端资源和服务端资源是一样的,没有被修改
- 服务端如何判断是否和缓存资源一致
- 图示 => 协商缓存
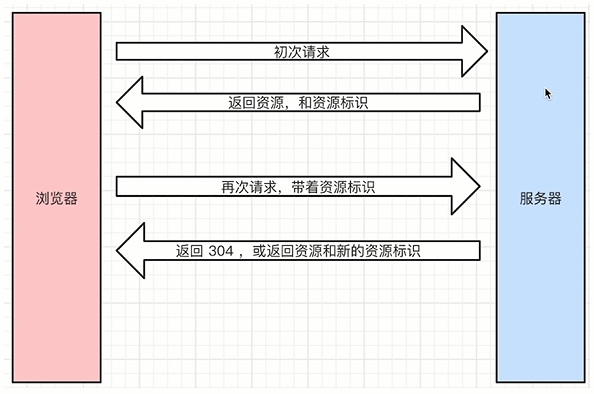
- 浏览器本身是自带一个缓存机制的,不过上图没有表现出来
- 存储服务器的缓存资源
- 根据图示梳理缓存流程
- 浏览器初次请求服务器
- 服务器返回资源和资源标识
- 标识资源的一个符号(字符串或者时间等)
- 资源标识比较短,体积小
- 浏览器再次请求,会带着资源标识
- 服务端根据资源标识判断当前资源是否是服务端最新的资源
- 返回304,或者返回200、新的资源和新的资源标识
- 图示 => 协商缓存
- 资源标识简介
- 在response headers中,有两种
- Last-Modified => 资源的最后修改时间
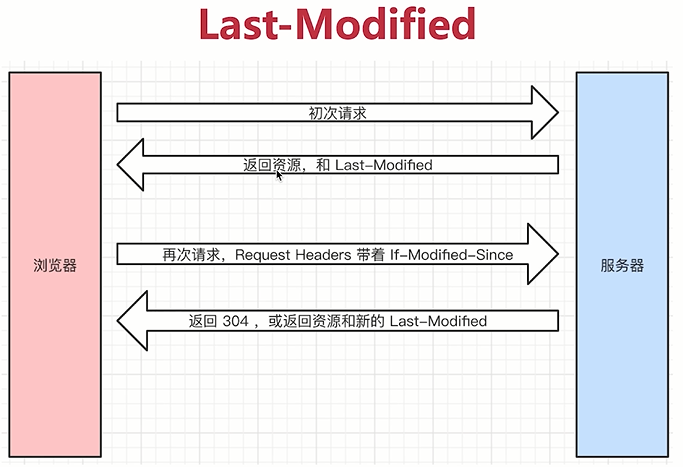
- 服务端返回资源和Last-modified
- 值是最后修改时间
- 浏览器再次请求的时候,请求头会带着If-Modified-Since
- If-Modified-Since是Last-Modified的key
- 值是最后修改时间
- 前端请求的和后端返回的资源标识名字不一样,但值是一样的
- url就可以代表这个资源,判断这个资源的最后修改时间是不是和带来的这个If-Modified-Since值是一样的
- 服务端会判断If-Modified-Since和Last-modified是否相等
- 这两个值相等,就返回304
- 服务端修改的话,会改变Last-Modified的值
- 服务端每返回一个Last-Modified,If-Modified-Since的值就会修改,服务端根据带来的时间和资源的最后修改时间做一个协商,做一个对比,看看能不能返回304
- 新的Last-Modified力求下次能命中缓存
- 服务端返回资源和Last-modified
- Etag => 资源的唯一标识(一个字符串,类似人类的指纹)
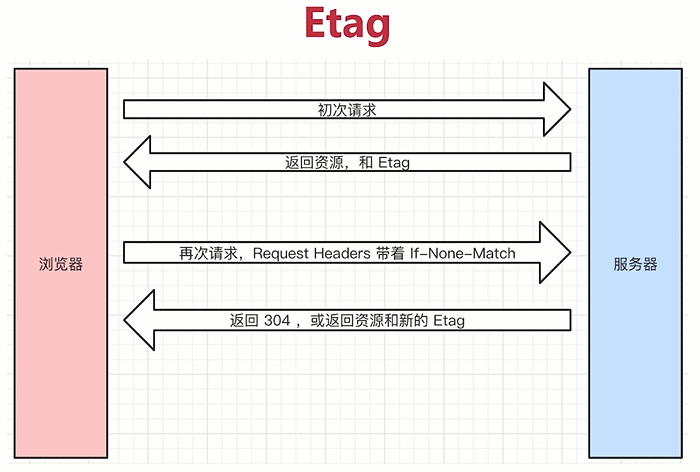
- 服务端返回资源和Etag(就是一个字符串),但是要保证唯一性
- 浏览器发现有Etag之后,就会把资源缓存下来,把Etag也记下来
- 浏览器再次请求,请求头带着If-None-Match
- 再次请求的时候请求头会带上If-None-Match,他的值实际上就是Etag
- 服务端发现有If-None-Match之后,服务端就会根据当前资源重新计算一个Etag,再和If-None-Match的值进行对比
- 如果这个资源没有变过,算出来的Etag应该和If-None-Match的值是一样的
- 如果对比值不一样,就会返回一个新的Etag和新的资源
- 返回304,或返回资源和新的Etag
- 服务端返回资源和Etag(就是一个字符串),但是要保证唯一性
- Last-Modified => 资源的最后修改时间
- 协商缓存图示
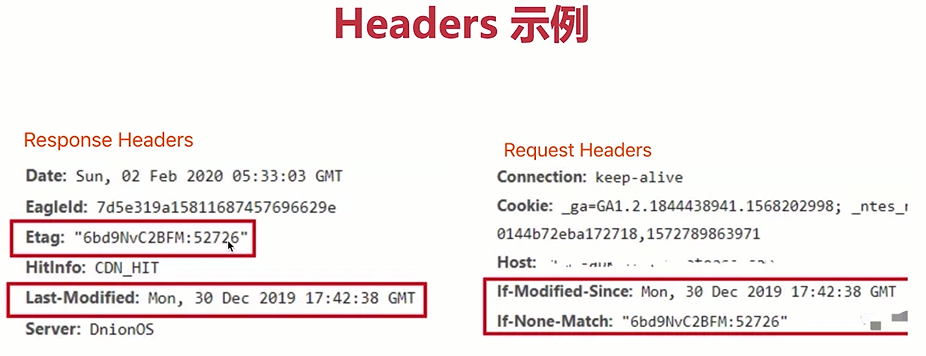
- 在response headers中,有两种
- Last-Modified和Etag注意事项
- 会优先使用Etag
- 因为Last-Modified只能精确到秒级
- 秒对计算机而言,是一个比较大的单位,以程序而言,一般是以毫秒为单位
- 如果资源被重复生成,而内容不变,则Etag更精确
- 如果资源1s生成一次,内容不变,Last-Modified每次都会过期,重新返回新资源
- Etag他是根据内容计算的(类似webpack的hash)
- 内容不变,就算1s重新生成一次,他的Etag值也不会变化
- 会优先使用Etag
3.4.2.3. 缓存总结(重点)
- 如图所示
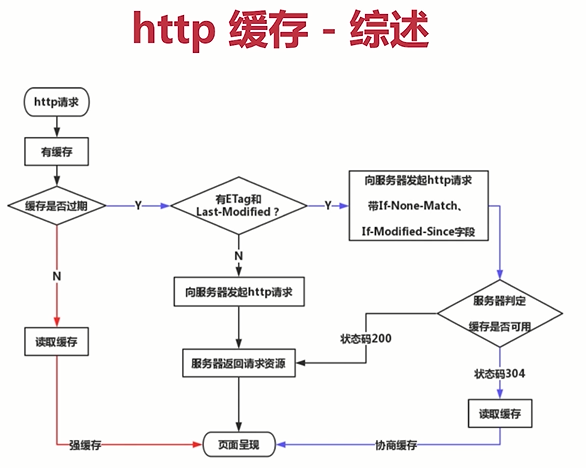
- 根据图示梳理缓存流程
- 第一种情况
- 发送http请求
- 如果有缓存
- 判断缓存是否过期
- Cache-Control里面有个max-age,即最大缓存时间
- 如果没有过期
- 读取缓存 => 强缓存
- 页面呈现
- 第二种情况
- 发送http请求
- 如果有缓存
- 如果缓存过期
- 判断有没有Etag或Last-Modified
- 可以同时存在
- 如果没有,就直接向服务器发起http请求
- 服务器返回请求资源
- 页面呈现
- 第三种情况
- 发送http请求
- 如果有缓存
- 如果缓存过期
- 判断有没有Etag或Last-Modified
- 如果有则向服务器发起http请求,并且带上If-None-Match或If-Modified-Since字段
- 可以同时存在
- 服务器判断缓存是否可用
- 如果不可用,直接请求服务器资源,返回200
- 页面呈现
- 第四种情况
- 发送http请求
- 如果有缓存
- 如果缓存过期
- 判断有没有Etag或Last-Modified
- 如果有则向服务器发起http请求,并且带上If-None-Match或If-Modified-Since字段
- 服务器判断缓存是否可用
- 如果缓存可用,返回状态码304
- 读取缓存(协商缓存)
- 页面呈现
- 第一种情况
- 注意事项
- 强制缓存判断在客户端
- 协商缓存判断在服务端
3.4.3. 三种刷新操作方式,对缓存的影响
- 三种刷新操作
- 正常操作:地址栏输入url,跳转链接,前进后退等
- 手动刷新:F5(mac使用commond+r),点击刷新按钮,右击菜单刷新
- 强制刷新:ctrl+F5(mac使用shift+commond+r)
- 刚上线可能有一些缓存
- 不同刷新操作,不同的缓存策略
- 正常操作:强制缓存有效,协商缓存有效
- 对大部分用户都有效
- 手动刷新:强制缓存失效,协商缓存有效
- 如果所用的操作都可以命中强制缓存,协商缓存就没有用了
- 强制缓存判断在客户端
- 协商缓存判断在服务端
- 只有协商缓存也会让页面加载地更快一些
- 强制刷新,强制缓存失效,协商缓存失效
- 不管多慢,都要全部返回最新的资源
- 正常操作:强制缓存有效,协商缓存有效
3.4.4. http的缓存小结
- 强制缓存 => Cache-Control
- 协商缓存 => Last-Modified和Etag,304状态码
- 完整的流程图(要求会自己画)
4. 面试题解答(总结)
- http最基本的知识体系
- 状态码
- http method
- restful api
- http headers
- http缓存策略
- 知识点
- http常见的状态码有哪些
- 先从状态码范围开始
- 讲一些常用的状态码(200、301、302、304、404、403、500、504)
- 504 => 网关超时
- 304 => 资源未被修改、和缓存策略有关
- 301 => 永久重定向
- 302 => 临时重定向
- http常见的header有哪些
- 请求头
- Accept
- 浏览器可接收的数据格式
- Accept-Encoding
- 浏览器可接收的压缩算法
- Connection
- keep-alive一次TCP连接重复使用
- cookie
- Host
- 请求的域名
- User-Agent
- 浏览器信息
- Content-type
- 发送数据的格式
- Accept
- 响应头
- Content-type
- 返回的数据格式
- Content-length
- 返回数据的大小(字节)
- Content-Encoding
- 返回数据的压缩算法(gzip)
- Set-Cookie
- 服务端改cookie的时候,通过Set-Cookie修改
- Content-type
- 缓存相关的headers
- Cache-Control
- 强制缓存
- max-age(最大缓存时间)、no-cache(不用强制缓存)
- Expires
- 强制缓存(旧版本)
- Last-Modified
- 协商缓存,服务端返回,时间,单位秒
- IF-Modified-Since
- 协商缓存,客户端请求,时间,单位秒
- Etag
- 协商缓存,服务端返回,唯一字符串,根据资源内容计算
- If-None-Match
- 协商缓存,客户端请求,唯一字符串,根据资源内容计算
- Cache-Control
- 自定义头信息
- 应用于登陆等场景
- 请求头
- 什么是restful api
- 4个method说明白
- post、get、patch(修改)、delete
- 设计理念
- 传统的API设计:把每个url当作一个功能
- Restful API设计:把每个url当作一个唯一的资源(标识)
- 4个method说明白
- http常见的状态码有哪些
- 面试题
- 描述一下http的缓存机制
- 缓存包括强制缓存和协商缓存
- 强制缓存主要需要理解Cache-Control
- 协商缓存主要理解Last-Modified和Etag,以及304的概念
- 具体见上文 => 缓存总结(图文)
- 描述一下http的缓存机制