 zmx2321
zmx2321前端开发面试题集
开场与自我介绍
面试官好,我叫陈民,有 6 年以上政企数字化与智慧城市领域经验。以 Vue 全家桶为核心,专注 GIS 可视化(OpenLayers/Mapbox/Cesium),同时具备数据处理能力,能通过 Python 与 PostgreSQL(PostGIS)完成数据采集、清洗到地理化存储。
近年在中国移动设计院,负责无线网质量评估系统的 GIS 模块、AI 助手及 Python 数据自动化同步,熟悉政企项目规范与业务流程,可独立完成核心模块开发与交付,也能熟练使用 Cursor 等 AI 工具提升效率,适配政企项目节奏。
---- Vue3原理与TypeScript专项 ----
TypeScript中interface和type的区别是什么?
参考答案:
相同点:都可描述对象类型,都可被扩展(extends/交叉类型)。
不同点:
interface可以重复声明合并,type不可重复声明。
interface只能表示对象类型,type可表示原始类型、联合类型、元组等。
type可使用in关键字生成映射类型,interface不能。
继承方式:interface使用extends,type使用交叉类型(&)。
什么是泛型?请举例说明在日常开发中的应用。
参考答案: 泛型(Generics)是指在定义函数、接口或类时,不预先指定具体类型,而在使用时再指定,以提高复用性。 例子:
// 泛型函数
function identity<T>(arg: T): T {
return arg;
}
// 泛型接口
interface KeyValuePair<K, V> {
key: K;
value: V;
}
// 泛型约束
function getProperty<T, K extends keyof T>(obj: T, key: K) {
return obj[key];
}// 泛型函数
function identity<T>(arg: T): T {
return arg;
}
// 泛型接口
interface KeyValuePair<K, V> {
key: K;
value: V;
}
// 泛型约束
function getProperty<T, K extends keyof T>(obj: T, key: K) {
return obj[key];
}TypeScript中any和unknown的区别是什么?
参考答案:
any:关闭类型检查,可赋值给任何类型,也可被任何类型赋值,会污染其他变量。
unknown:类型安全的any,只能赋值给any或unknown自身,使用前必须进行类型断言或收窄(typeof、instanceof等)。
在原理层面上讲vue2和vue3有什么区别
- 对于vue而言,本质上我们可以将它们分成三大模块,响应性reactivity,运行时runtime,编译器compiler,
- 先说响应性,vue2通过Object.definedProperty()去实现响应性,但是这种方法的核心是用来监听指定对象的指定属性的get、set行为,在这种情况下,就会出现一些问题,比如说在vue2的data中声明了一个对象,那么给这个对象在后期某一个时刻去新增属性的时候,因为js本身的限制,我们没办法监听到这个对象新增的这个属性,这个时候,我们就没办法通过Object.definedProperty()去监听对应的新增属性的行为,所以新增的这个属性就不是响应式的了,vue2为了解决这个问题,提供了vue.$set的方法,这个方法本质上就是把这个属性和对象过了一遍Object.definedProperty(),这种方案从程序设计的理念上看,不是很合理, 所以在vue3的时候,他提供了es6新出现的反射和代理的概念,反射指的就是reflect,代理指的就是proxy,他通过proxy来代理了一个复杂的数据类型,通过这样复杂数据类型的代理,我们得到了一个代理对象,就是proxy的实例,然后通过reflect来确定了this上的一个指向,vue3中实现这样的一套流程的方法就是我们常见的raactive,但对于proxy而言,他只能去监听复杂数据类型的响应式,而没办法监听简单数据类型的响应式,比如基本的string和int, 所以vue3里面又提供了ref的方法,ref的方法本质上其实就是把内容分成了两部分,第一部分就是复杂数据类型,在vue内部会直接通过toRective的方法指向reactive, 第二部分的简单数据类型,其实在内部会去处理一个refImpl,也就是ref imploment的一个接口,通过这个接口内部,他实现了两个方法,一个叫做get标记的value,一个叫做set标记的value,通过ref这样的形式,当我们去触发.value这个属性的时候,本质上就是在触发他的value方法,这是响应性上的
- 除此之外还涉及到运行时的runtime的行为,runtime其实大部分指的就是所谓的渲染器也就是render,在这个渲染器对象里面,包含了一个我们常见的渲染函数即render函数,这个render函数内部把宿主环境,也就是所谓的浏览器,或者说是uniapp,uniapp可以使用vue进行渲染的原因,本质上就是因为vue在runtime阶段去进行了一个宿主环境和渲染逻辑的分离
- 第三个就是所谓的编辑器,编辑器我们一般情况下分成三个阶段parse阶段,transform阶段,generate阶段,编辑器本质上就是把template,编辑成为了一个render的函数,在vue3中,他将这个阶段进行了系统的划分,我们可以直接通过baseparse把template直接转化成ast,就是动态抽象语法树,然后利用transfrom把js转化为jsast,就是js标记的抽象语法树,然后再通过generator把jsast拼接成一个render的渲染函数
- 在vue3里面,在项目中要用到的,甚至是一些生命周期,都需要import进行动态导入,这样做的目的是为了更好的 Tree-shaking,因此可以更好地剔除不需要的代码 ●通过main.js可以看出来,vue2整个构造是基于原型链的,vue3主要使用函数去构造的
- vue3中可以没有根标签,实际上他会默认将多个根标签包裹在一个fragement虚拟标签中,有利于减少内存
- Vue 3 的代码库已经全面采用 TypeScript 重写,提供了更好的类型推断和类型提示
- 在vue2中v-for的优先级高于v-if,可以放在一起使用,但是不建议这么做,会带来性能上的浪费,在vue3中v-if的优先级高于v-for,一起使用会报错。可以通过在外部添加一个标签,将v-for移到外层
- diff算法不同,vue2中的diff算法,遍历每一个虚拟节点,进行虚拟节点对比,并返回一个patch对象,用来存储两个节点不同的地方。用patch记录的消息去更新dom
- vue3中的diff算法,在初始化的时候会给每一个虚拟节点添加一个patchFlags,是一种优化的标识。只会比较patchFlags发生变化的节点,进行视图更新。而对于patchFlags没有变化的元素作静态标记,在渲染的时候会直接复用。
- 在使用上,目前使用vue3的话,状态管理从vuex换成了pina,事件总线使用的是mitt
--- 通用基础与前端深度 ---
有使用过原生js吗
- 原生js的操作可以分为Dom操作和Bom操作,还有其他一些js api的操作,bom操作,其实就是浏览器相关的操作,比如获取浏览器信息的navigator,获取url信息的location,对浏览器url进行操作的history等
- 对于dom操作的话,主要就是针对html元素的一些增删改查
- 先说dom的新增,比如我们根据http请求,获取并处理好了一些数据,并组成了一段html代码片段,需要将他插入到dom里面的话,可以使用appendChild,但如果我们需要完全替换掉盒子里面的内容的话,可以使用innerHtml,如果我们为了在一个空的盒子里面需要创造一些元素的话,我们可以使用createElement,我们知道,DOM操作比较耗时,我们有时候为了避免频繁的操作dom元素,会对dom进行缓存,就需要使用到dom的代码片段,createDocumentFragment
- 再说说dom的删除,dom的删除其实就是removeChild
- 再说说dom的修改,dom节点的修改实际上就是将innerHtml与appendChild联合起来使用,dom节点上属性的修改,有修改对象属性property,和修改html属性两种,前者不会体现在html中,例如p.style.color,后者会改变html结构,需要使用setAttribute(键值对)、getAttribute
- 最后说一说dom结构的查询,主要就是如何获取dom节点,比如根据id查找,根据类名查找,根据标签名查找,还有就是querySelector、querySelectorAll
- 其他的非dom的原生js操作,有数组操作,xhr的一些操作,正则的一些操作等
请解释JavaScript中的防抖和节流,并写出简单实现
- 防抖(Debounce):在事件被触发n秒后执行回调,若n秒内再次触发则重新计时。适用于输入框搜索、窗口调整等。
- 延迟执行
// 延迟时间默认500毫秒
const debounce = (fn, delay = 500)=> {
// timer是在闭包中的 => 下面的if(timer)
// 这样不会被外界轻易拿到 => 即不对外暴露
// 我们在外面使用不需要关心
// 同时也是在debounce的作用域中
// 闭包的使用场景:函数当做返回值或者参数传入
let timer = null;
// 函数作为返回值,这就形成闭包了
return function() {
// 这里面的timer需要在它定义的作用域往上寻找
if(timer) {
clearTimeout(timer)
}
timer = setTimeout(()=> {
// 第一个参数是改变this指向
// 第二个参数是获取所有的参数
// apply第二个参数开始,只接收数组
// fn函数在执行的时候,argument传进来
// debounce返回的函数可能会传进来一些参数
fn.apply(this, arguments)
// 清空定时器
timer = null
}, delay)
}
}// 延迟时间默认500毫秒
const debounce = (fn, delay = 500)=> {
// timer是在闭包中的 => 下面的if(timer)
// 这样不会被外界轻易拿到 => 即不对外暴露
// 我们在外面使用不需要关心
// 同时也是在debounce的作用域中
// 闭包的使用场景:函数当做返回值或者参数传入
let timer = null;
// 函数作为返回值,这就形成闭包了
return function() {
// 这里面的timer需要在它定义的作用域往上寻找
if(timer) {
clearTimeout(timer)
}
timer = setTimeout(()=> {
// 第一个参数是改变this指向
// 第二个参数是获取所有的参数
// apply第二个参数开始,只接收数组
// fn函数在执行的时候,argument传进来
// debounce返回的函数可能会传进来一些参数
fn.apply(this, arguments)
// 清空定时器
timer = null
}, delay)
}
}- 节流(Throttle):规定一个单位时间内只触发一次函数。适用于滚动加载、频繁点击、拖拽等。
- 单位时间执行一次
const throttle = (fn, delay = 100)=> {
let timer = null // 这个timer是在闭包里面的
// 如果不使用apply改变this指向,下面的throttle方法的参数指向这个函数
// 不会传给下面的那个fn
return function() {
if(timer) {
return
}
timer = setTimeout(()=> {
// 一般写一个事件,function里面都要加上event参数,即事件对象
fn.apply(this, arguments) // 打印坐标
timer = null
}, delay)
}
}const throttle = (fn, delay = 100)=> {
let timer = null // 这个timer是在闭包里面的
// 如果不使用apply改变this指向,下面的throttle方法的参数指向这个函数
// 不会传给下面的那个fn
return function() {
if(timer) {
return
}
timer = setTimeout(()=> {
// 一般写一个事件,function里面都要加上event参数,即事件对象
fn.apply(this, arguments) // 打印坐标
timer = null
}, delay)
}
}什么是闭包
- 闭包的核心是内层函数访问外层函数的变量,且外层函数执行完变量不销毁;
- 防抖、节流都有用到闭包,其中的timer外层变量,被内层函数访问,不会被销毁
// 外层函数
function outerFunc() {
// 外层函数的变量
const city = "杭州";
// 内层函数(闭包)
function innerFunc() {
// 内层函数访问外层变量 → 形成闭包
console.log(`我在${city}做GIS开发`);
}
// 返回内层函数,让它能在外部被调用
return innerFunc;
}
// 执行外层函数,得到内层函数
const myFunc = outerFunc();
// 此时outerFunc已经执行完,但innerFunc仍能访问city变量
myFunc(); // 输出:我在杭州做GIS开发// 外层函数
function outerFunc() {
// 外层函数的变量
const city = "杭州";
// 内层函数(闭包)
function innerFunc() {
// 内层函数访问外层变量 → 形成闭包
console.log(`我在${city}做GIS开发`);
}
// 返回内层函数,让它能在外部被调用
return innerFunc;
}
// 执行外层函数,得到内层函数
const myFunc = outerFunc();
// 此时outerFunc已经执行完,但innerFunc仍能访问city变量
myFunc(); // 输出:我在杭州做GIS开发性能和体验的优化
从浏览器输入到页面展示做了什么
- 在用户输入到展示的几秒钟里面,浏览器会经历一系列复杂步骤将网页内容呈现在屏幕上
- 计算机主要做了两个事情,一个是加载资源,一个是渲染页面
- 同时总体可以分为四个大步骤
- DNS解析 => TCP连接 => HTTP请求 => 渲染页面
DNS解析
- 刚开始浏览器会对输入的url进行解析,提取出协议,主机名,路径等信息,这里面涉及到http和https的一些概念,如果是https的话,为了安全,会去做一些处理
- 接下来浏览器会将主机名转换成对应的ip,这个过程被称之为dns解析
- 浏览器会首先检查本地的dns缓存,如果有匹配的ip直接进行访问,如果没有的话,会向dns服务器发送请求,来获取对应的IP地址
TCP连接
- 转换成ip之后,浏览器会通过ip地址和端口号来与服务器建立tcp链接,这个过程是通过tcp的三次握手完成的,以确保双方可以正常通信
- 第一次握手,客户端发送syn包到服务器,并且客户端进行syn_send状态,等待服务器确认
- 第二次握手,服务器接收到syn包时,会发送一个syn+ack包给客户端,服务器进入syn_recv状态
- 第三次握手,客户端接收到syn+ack包之后,向服务器发送确认ack的包,至此三次握手结束
- 简易记法
- 发送方(计算机A)先传达一个连接意愿 => 在吗,来一把?
- 接收方(计算机C)收到连接意愿后,回复一个连接确认,表示同意连接 => 在,来吗
- 发送方(计算机A)收到连接确认后,再次发送一个连接确认,表示连接成功 => 来了,来了
HTTP请求
- 建立tcp连接之后,客户端与服务器就开始传输数据了
- 首先浏览器会向服务器发送http请求,请求的内容包括方法,请求头部,和请求体等
- 如果是get请求,请求体在url上
- 请求头包括浏览器自带的请求头和自定义的请求头,自定义的请求头可以用于登陆等场景
- 浏览器自带的请求头包括浏览器的一些信息,浏览器可接收的压缩算法,浏览器可接收的数据格式,content-type,accept等等
- 服务器接收到浏览器发送的请求之后,会进行处理,包括读取数据库,处理一些业务逻辑,生成一些动态内容等
- 服务器处理完请求,会对处理结果封装成http响应,包括状态码,响应头部,响应体等
- 浏览器自带的响应头也包含content-type,除此之外还有返回数据的压缩算法格式等,服务器修改cookie时,通过set-cookie修改
- 浏览器接收到服务器的响应后,会对这个响应进行解析,如果响应体是html文档,则会下载其中引用的其他资源,例如js,css,静态文件等
- 响应结束之后,为了更彻底地释放双方的资源,引入了四次挥手
- 四次挥手的时间,看是否设置了keep alive属性
- 第一次挥手,客户端发送终止请求报文段
- 第二次挥手,服务器接收到请求并发送确认报文
- 第三次挥手,客户端收到确认并发送确认报文
- 第四次挥手,服务器接收到确认报文并终止连接
- 简易记法
- 发送方(计算机A)先传达一个关闭意愿 => 要不退了吧
- 接收方(计算机C)收到关闭意愿后,回复一个关闭确认,表示同意关闭 => 行,等我这把刷完
- 接收方(计算机C)数据处理完毕,再向计算机A传达一个关闭意愿 => 刷完了,你可以退了
- 发送方(计算机A)收到关闭确认后,再次发送一个关闭确认,表示关闭成功 => 你也退吧,下次别再打野了
- 四次挥手的时间,看是否设置了keep alive属性
- 在请求和响应的过程中,中间还有一个很重要的步骤,就是浏览器的缓存
- 浏览器的缓存主要包括强制缓存和协商缓存,强制缓存的判断主要在客户端,协商缓存的判断主要在服务端
- 强制缓存主要使用cache-control,浏览器初次请求到服务器时,服务器不止返回资源,还会返回一个cache-control,客户端如果看到有这个标识,会将资源缓存下来,后面请求的时候会看这个标识是否过期,不过期的话就不进行请求
- 协商缓存主要使用last-modified和etag进行标识,服务端会对客户端请求的资源进行判断,如果请求的资源时一样的,就会返回304,否则就会返回200
- http缓存不一定只用一种方式,经常会一起使用,这时候就要了解两种缓存的执行流程
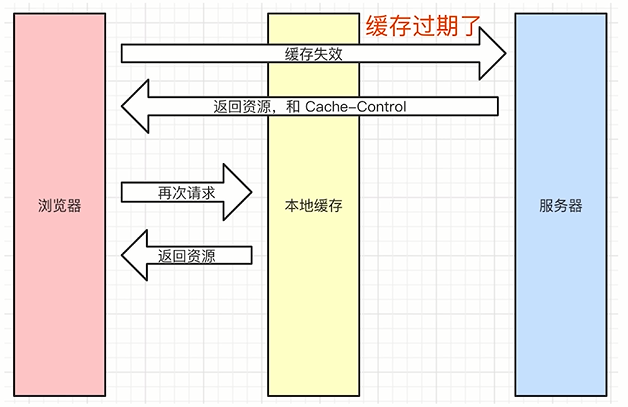
- 发送http请求,一般来说,首先是判断是否命中强制缓存,再判断是否命中协商缓存,如果有强制缓存,但缓存过期,就会进入协商缓存的过程,如果服务端判断缓存不可用,即没有last-modified和etag标识或者标识不一致,就不会命中协商缓存,手动刷新的时候,协商缓存还是有效的,只有强制刷新,才能使两个缓存都失效
渲染页面
渲染流程的简单回答
- 解析下载完资源之后,浏览器会将html解析器解析成dom树,然后使用css解析器将css文件解析成样式规则,接着,浏览器根据dom树和样式规则进行渲染,将页面内容显示在浏览器上
- 浏览器根据html代码生成文档对象模型树(DOM Tree),浏览器根据css代码生成css对象模型(cssOM),再将文档对象模型树和css对象模型整合形成渲染树(Render Tree),浏览器根据渲染树渲染页面,如果遇到
<script>则暂停渲染,优先加载并执行JS代码,完成再继续,js和渲染是共用一个线程的,因为js有可能会改变渲染树结构,当JS代码执行完之后,再继续进行渲染,直到渲染树渲染完成
渲染流程的完整回答
- 以上只是浏览器渲染页面的简单描述,实际上,浏览器在渲染页面这一步做的步骤非常多,要了解其中的步骤,首先需要了解浏览器的进程模型
- 我们知道软件的运行时需要开启进程的,浏览器也是,浏览器是一款多进程多线程的应用程序,浏览器的内部工作极其复杂,复杂程度已经堪比一个操作系统了
- 当浏览器启动之后,它会自动启动多个进程,每个进程都有独立的内存空间,进程之间相互独立,互不干扰,浏览器启动的进程主要有以下几种
- 浏览器进程
- 主要用来做界面展示,用户交互,子进程管理,同时浏览器进程内部会启用多个线程处理不同的任务
- 渲染进程(我们需要了解的重点)
- 浏览器启动之后,会自动打开一个标签页,这个标签页就是一个渲染进程,即一个标签页一个渲染进程
- 网络进程,等等……
- 浏览器进程
- 在渲染进程启动后,会开启一个渲染主线程,这个线程是浏览器中最忙的“人”,它要负责解析 HTML、CSS,执行 JavaScript,计算布局,绘制页面等等。因为任务太多,它需要排队处理——这就是我们常说的事件循环(也叫消息循环)。
- 当网络线程拿到 HTML 文档后,会生成一个渲染任务扔进消息队列。渲染主线程一旦发现队列里有任务,就取出来开始执行,这一取,就开启了整个渲染流程。
- 整个渲染流程就像一条流水线,每个环节的输出会成为下一个环节的输入。大致分为以下几个阶段:
- 解析 HTML:主线程会从头解析 HTML 代码,一边解析一边生成 DOM 树。如果遇到 引用外部 CSS,浏览器会启动预解析线程去下载,主线程继续往下走,所以 CSS 不会阻塞 HTML 解析。但如果遇到
<script>,主线程就必须停下来,等 JS 下载并执行完才能继续,因为 JS 可能会修改 DOM。这一步结束后,我们有了 DOM 树和 CSSOM 树(样式表)。 - 样式计算:主线程遍历 DOM 树,结合 CSSOM 为每个节点算出最终的样式(比如把 red 转成 rgb(255,0,0),把 1em 转成 16px)。这步完成后,每个 DOM 节点都带上了计算后的样式。
- 布局:这一步要算出每个节点在页面上的精确位置和大小。主线程会遍历带样式的 DOM 树,生成一棵布局树。注意,布局树和 DOM 树不一定一一对应,比如 display: none 的元素不会出现在布局树里,而伪元素(::before)虽然不在 DOM 树中,但会出现在布局树里。布局树里的每个节点都包含了宽、高、相对包含块的位置等信息。
- 分层:为了提升后续渲染效率,浏览器会把布局树分成多个独立的图层。比如有堆叠上下文(z-index、transform、opacity 等)的元素可能会单独一层,滚动条也会单独一层。这样如果某一层内容变了,只需要重新处理那一层,不用重画整个页面。你也可以用 will-change 提示浏览器让某个元素单独分层。
- 绘制:有了图层,主线程会为每个图层生成一套绘制指令。这些指令就像在说“先画一个矩形,再画一行文字,再画一个圆”……这一步完成后,主线程的任务就告一段落,后续工作交给合成线程。
- 分块:合成线程会把每个图层切成许多小块(tiles),因为屏幕可能很大,优先处理靠近视口(当前可见区域)的块。这个过程会启动多个分块线程同时进行。
- 光栅化:分块完成后,合成线程把每个小块交给 GPU 进程去转换成位图(也就是像素点颜色信息)。GPU 特别擅长这种计算,所以速度很快。光栅化后的结果就是一块块位图。
- 画:最后,合成线程拿着这些位图,再算出每个位图应该放在屏幕的哪个位置(可能还要考虑旋转、缩放等变形),然后把信息交给 GPU 进程,由 GPU 进程通过系统调用真正显示在屏幕上。这一步就是 draw quad。
- 解析 HTML:主线程会从头解析 HTML 代码,一边解析一边生成 DOM 树。如果遇到 引用外部 CSS,浏览器会启动预解析线程去下载,主线程继续往下走,所以 CSS 不会阻塞 HTML 解析。但如果遇到
- 补充说明
- 如果修改了元素的几何信息(比如宽高、位置),就会触发重排(reflow),需要重新走布局、分层、绘制……整个过程代价很大。
- 如果只修改颜色、背景等不影响布局的属性,只会触发重绘(repaint),不需要重新布局,但还是要重新生成绘制指令。
- 而像 transform 这样的属性,因为它只影响元素最后的变形,不改变布局和绘制指令,所以它的动画完全在合成线程处理,即使主线程卡死,动画也能流畅运行。这就是 transform 高效的根本原因。
常见的请求头和相应头有哪些
请求头
请求头主要是客户端向服务端发送的请求,主要有:
- Accept => 浏览器可接收的数据格式(text/html、application/json等)
- Accept-Encoding => 浏览器可接收的压缩算法,如gzip
- 我们可以根据gzip算法把资源进行压缩(100kb大概可以压缩至30kb左右)
- 浏览器告诉服务器,我能接收什么样的压缩算法,服务器就会根据Accept-Encoding的压缩算法进行压缩为了保证资源更小,传输地更快一些,前端也可以正常地解压出来
- Accept-Language => 浏览器可接收的语言,如zh-CN
- Connection => keep-alive一次TCP连接重复使用
- 每次请求重新建立TCP连接会很消耗资源,我们和服务端建立了连接之后,就可以重复地使用这个连接,没必要断开之后重连,可以重复地使用一次连接,把资源一次性请求完成,现在的浏览器版本基本上都是支持keep-alive的
- cookie => 同域,每次请求资源的时候都会把cookie带上,浏览器自己带的
- Host => 请求的域名是什么
- User-Agent(简称UA) => 浏览器信息 => 重点
- 能标识你的浏览器信息(类型等)
- 服务端能够接收ua信息,可以判断用户使用的浏览器类型
- Content-type
- 发送数据的格式,如 application/json
- 客户端向服务端请求,要发送一些数据的时候(post),告诉服务端,我们这个数据是什么格式的,一般get请求是没有的,get请求主要是向服务端获取数据
响应头
Content-type => 返回的数据格式
- Content-type => 返回的数据格式
- 如 application/json
- Content-length => 返回数据的大小,多少字节
- Content-Encoding => 返回数据的压缩算法,如gzip
- 客户端告诉服务端支持的压缩算法之后,服务端根据压缩算法进行压缩,服务端压缩之后会通过Content-Encoding告诉客户端我是用什么算法压缩的,浏览器会自动根据这个压缩算法解压
- Set-Cookie
- 服务端改cookie的时候,通过Set-Cookie修改
自定义header
之前说的请求头和响应头是浏览器自带的,或者服务端和浏览器配合加的,但请求头和响应头实际上可以自定义header,自定义请求头的时候,需要前后端进行约定,一般用在简单的权限校验,但不要和浏览器自带的键值冲突
缓存相关的header
- Cache-Control(响应头)、Expires(响应头)、Last-Modified(响应头)、IF-Modified-Since(请求头)、Etag(响应头)、If-None-Match(请求头)
简单介绍一下http的缓存
浏览器访问一个新的网站,服务端会返回所有的资源,并且浏览器或者服务器会将一些不必要重新获取的资源存到缓存区,第二次访问的时候,就不需要全部重新获取一遍资源,有一部分资源会从缓存中获取,即我们可以把一些没有必要重新获取的资源不再重新获取,这就是缓存,http缓存有两种,一种是强制缓存,一种是协商缓存,强制缓存是在有效期内,客户端都不需要经过网络,但协商缓存是每次都要经过网络,但如果命中缓存,即数据没有变化,会返回304,让客户端从缓存获取数据,以下是http的缓存策略的简单介绍:
http的缓存策略主要有两种,强制缓存和协商缓存
强制缓存:
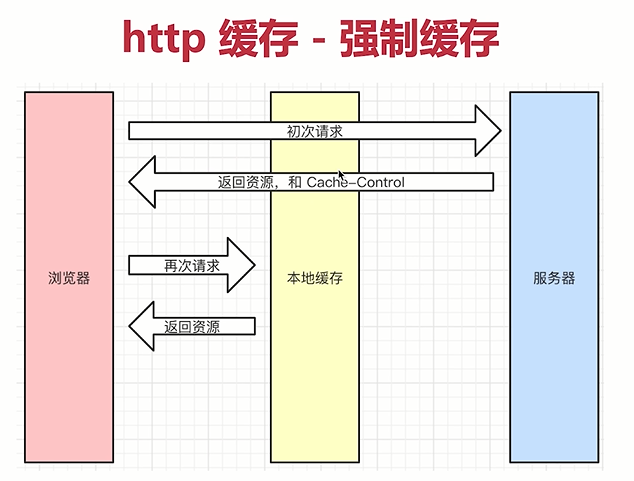
- 当浏览器初次请求到服务器之后,如果服务端感觉这个资源可以被缓存,服务端会返回结果集和一个响应头Cache-Control,如果服务端感觉这个资源不适合被缓存,就不会加上这个响应头,一般些静态资源(js、css、img)都会被加上这个响应头,如果浏览器识别到这个响应头,则会将资源缓存下来
- 当浏览器再次请求的时候,他会在客户端判断Cache-Control这个响应头时间是否过期,如果时间没有过期,浏览器就会在本地缓存中获取资源,直接返回,不会经过经过网 络,如果响应头时间过期了,则继续执行初次请求的步骤
- 服务端控制哪些资源可以加Cache-Control,客户端控制不了,强制缓存本质还是服务端控制的,但在表现上,只要本地的Cache-Control不过期,客户端会先从本地缓存里面找,找到了就判断是否过期
- 强制缓存也可以用Expires来体现,但是因为Expires使用的是绝对时间,如果客户端和服务端的时间不一致,可能会出问题,所以现在一般都使用Cache-Control
协商缓存,也叫对比缓存:
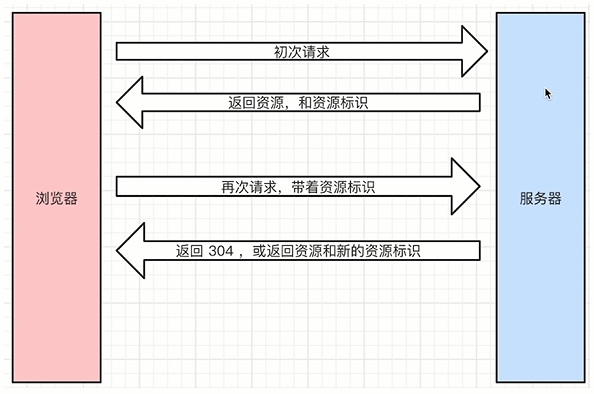
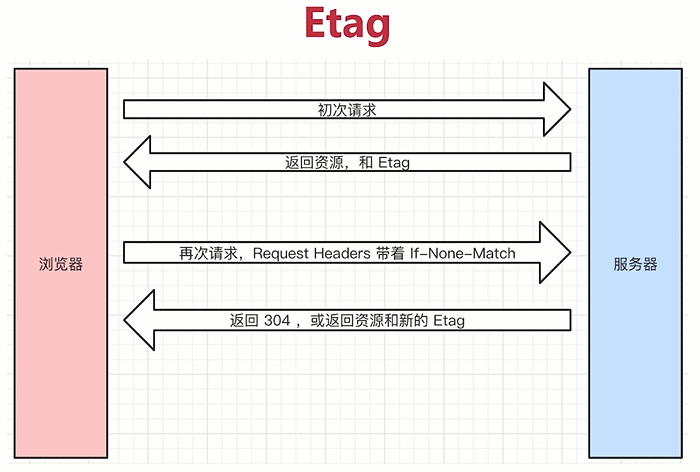
类似一个商量或者沟通的意思,由服务端来判断这个资源是否可以被缓存,我们这个资源到了服务端之后,服务端可以告诉浏览器这个资源没有动,可以直接用本地的缓存就可以了,一般用在客户端资源和服务端资源是一样的,没有被修改的时候,如果判断一致就返回304,否则返回200和最新的资源
浏览器初次请求服务器,服务器返回资源和资源标识,浏览器再次请求,会带着资源标识,服务端根据资源标识判断当前资源是否是服务端最新的资源
Cache-Control这个响应头主要和强制缓存有关,能简单介绍一下这个响应头吗
- max-age => 缓存最大过期时间(秒)
- max-age=31536000 (单位是秒 - 1年)
- 我们需要将某个资源文件在客户端缓存一年的时间,期间都不需要通过网络
- no-cache => 可以在客户端存储资源,但每次都必须去服务端做新鲜度校验
- 使用no-cache的目的就是为了防止从缓存中获取过期的资源
- 设置了该字段需要先和服务端确认返回的资源是否发生了变化,如果资源未发生变化,则直接使用缓存好的资源,即走协商缓存
- no-store(不常用) => 不用强制缓存,也不让服务端做缓存,让服务端直接返回资源
- private => 只能允许最终用户做缓存(设备)
- 设置了该字段值的资源只能被用户浏览器缓存,不允许任何代理服务器缓存。在实际开发当中,对于一些含有用户信息的HTML,通常都要设置这个字段值,避免代理服务器(CDN)缓存
- public(不常用) => 中间的代理也可以做缓存
- 设置了该字段值的资源表示可以被任何对象缓存
- 延伸:关于Expires
- 经常会和Cache-Control并列在一起,同样在响应头中,同为控制缓存过期,但已经被Cache-Control代替,现在的浏览器兼容这两种写法,如果同时存在,以Cache-Control为主
- Expires标识缓存到期时间,是一个绝对时间,如果客户端从他的缓存的这个字段里面找到这个时间,发现这个时间过期了,那就会发起网络请求去获取数据。
- 但是他的缺点也很明显,由于这个时间是绝对时间,那我客户端修改了本地时间,这个缓存不就失效了嘛。
- 为了解决Expires的问题,才引入了Cache-Control。Cache-Control代表了缓存的有效期,是一个相对时间,不管你客户端本地时间是什么,我只会返回给你一个有效期,相当于倒计时,只要这个倒计时到零了,你就给去获取缓存了。
简单介绍一下协商缓存的资源标识
- 在响应头中,协商缓存的资源标识主要有两种,Last-Modified和Etag
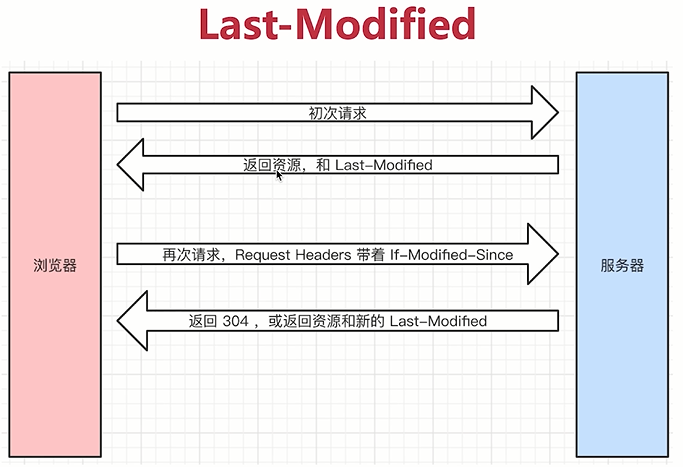
- Last-Modified => 值时资源的最后修改时间
- 浏览器第一次请求的时候,服务端返回资源和Last-modified,值是最后修改时间,浏览器再次请求的时候,请求头会带着If-Modified-Since,If-Modified-Since是Last-Modified的key,值也是最后修改时间,即前端请求的和后端返回的资源标识名字不一样,但值是一样的,url就可以代表这个资源,判断这个资源的最后修改时间是不是和带来的这个If-Modified-Since值是一样的,服务端会判断If-Modified-Since和Last-modified是否相等,这两个值相等,就返回304,服务端修改的话,会改变Last-Modified的值,服务端每返回一个Last-Modified,If-Modified-Since的值就会修改,服务端根据带来的时间和资源的最后修改时间做一个协商,做一个对比,看看能不能返回304,新的Last-Modified力求下次能命中缓存
- Last-Modified => 值时资源的最后修改时间
- Etag => 资源的唯一标识(值时一个唯一的字符串,类似人类的指纹)
- 服务端返回资源和Etag(就是一个字符串),但是要保证唯一性
- 浏览器发现有Etag之后,就会把资源缓存下来,把Etag也记下来
- 浏览器再次请求,请求头带着If-None-Match
- 再次请求的时候请求头会带上If-None-Match,他的值实际上就是Etag
- 服务端发现有If-None-Match之后,服务端就会根据当前资源重新计算一个Etag,再和If-None-Match的值进行对比
- 比如一些静态资源,比如webpack打包的时候,我们会加一个hash,hash是通过资源内容来算的,打包之后的静态资源文件,加上hash后缀之后,资源是不会被修改的,如果内容改了之后,会生成一个新的hash的名称
- 如果这个资源没有变过,算出来的Etag应该和If-None-Match的值是一样的,就会返回304
- 如果对比值不一样,就会返回一个新的Etag和新的资源
- Last-Modified和Etag的注意事项
- 会优先使用Etag,因为Last-Modified只能精确到秒级,秒对计算机而言,是一个比较大的单位,以程序而言,一般是以毫秒为单位
- 如果资源被重复生成,而内容不变,则Etag更精确,如果资源1s生成一次,内容不变,Last-Modified每次都会过期,重新返回新资源
- Etag他是根据内容计算的(类似webpack的hash),内容不变,就算1s重新生成一次,他的Etag值也不会变化
列举出浏览器缓存的所有情况
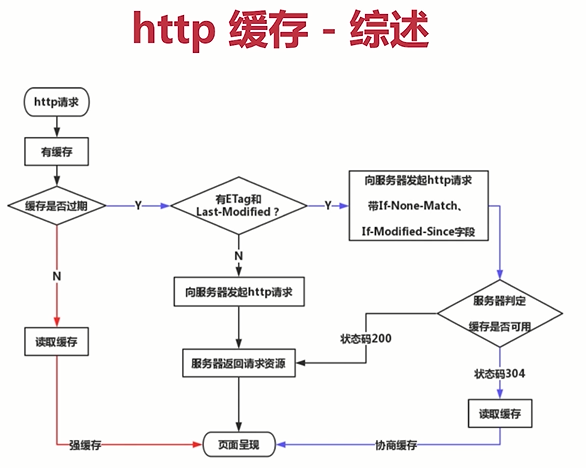
- 根据图示梳理缓存流程
- 第一种情况
- 发送http请求
- 如果有缓存
- 判断缓存是否过期
- Cache-Control里面有个max-age,即最大缓存时间
- 如果没有过期
- 读取缓存 => 强缓存
- 页面呈现
- 第二种情况
- 发送http请求
- 如果有缓存
- 如果缓存过期
- 判断有没有Etag或Last-Modified
- 可以同时存在
- 如果没有,就直接向服务器发起http请求
- 服务器返回请求资源
- 页面呈现
- 第三种情况
- 发送http请求
- 如果有缓存
- 如果缓存过期
- 判断有没有Etag或Last-Modified
- 如果有则向服务器发起http请求,并且带上If-None-Match或If-Modified-Since字段
- 可以同时存在
- 服务器判断缓存是否可用
- 如果不可用,直接请求服务器资源,返回200
- 页面呈现
- 第四种情况
- 发送http请求
- 如果有缓存
- 如果缓存过期
- 判断有没有Etag或Last-Modified
- 如果有则向服务器发起http请求,并且带上If-None-Match或If-Modified-Since字段
- 服务器判断缓存是否可用
- 如果缓存可用,返回状态码304
- 读取缓存(协商缓存)
- 页面呈现
- 第一种情况
不同刷新操作,不同的缓存策略
- 正常操作:强制缓存有效,协商缓存有效
- 对大部分用户都有效
- 手动刷新:强制缓存失效,协商缓存有效
- 如果所用的操作都可以命中强制缓存,协商缓存就没有用了
- 强制缓存判断在客户端
- 协商缓存判断在服务端
- 只有协商缓存也会让页面加载地更快一些
- 强制刷新,强制缓存失效,协商缓存失效
- 不管多慢,都要全部返回最新的资源
---- GIS开发深度(含Cesium专项) ----
你在无线网质量评估系统中基于Openlayer封装了核心方法。请详细说明封装了哪些方法?如果是Mapbox,如何解决WGS84和Web Mercator坐标系的转换问题?
参考答案: 封装的方法:初始化地图、添加/移除图层、绘制点/线/面、坐标转换、气泡窗渲染、地图缩放至指定范围、图层的显隐控制等。 Mapbox默认使用Web Mercator,但接收WGS84坐标时可直接传入(经度,纬度),Mapbox内部自动转换。如需手动转换,可使用ol/proj或Mapbox的MercatorCoordinate类进行投影转换。
你在德慧信息负责过Cesium二次开发。请解释什么是“模型单体化”?在项目中如何实现“点击模型联动加载关联业务数据”?
参考答案: 模型单体化是指将三维模型中的每个独立建筑或设备变为可点击、可高亮、可查询的个体。在项目中,通过Cesium的Entity或3D Tiles的batchId实现。加载倾斜摄影模型后,通过后端提供的构件ID与模型顶点颜色或属性表关联,利用pick事件获取点击的模型对象,根据batchId查询业务数据库,然后通过事件总线将数据传递给图表组件渲染。
在什么场景下你会选择用Openlayer/Mapbox,什么场景下必须用Cesium?对于智慧楼宇项目,用三维GIS(Cesium)和用三维游戏引擎(Unity/UE)做可视化有什么区别?
参考答案:
Openlayer/Mapbox:适合二维地图、业务系统、大屏二维可视化,轻量高效。
Cesium:适合全球尺度、地形、倾斜摄影、大规模三维数据场景,如智慧城市、应急指挥。 智慧楼宇选择:Cesium优势在于与GIS数据无缝集成,可叠加城市级底图,但室内精细度不如Unity/UE;游戏引擎适合高精度渲染、复杂交互,但难以处理大规模地理坐标和实时数据接入。根据需求:侧重室内漫游、高画质用Unity;侧重宏观位置、周边地理分析用Cesium。
当GIS地图上有上万个点位需要渲染时,你会采用哪些技术手段保证浏览器不卡顿?
参考答案:
点聚合:使用Openlayer的Cluster源或Mapbox的聚类功能,将邻近点聚合成一个点。
矢量瓦片:后端生成矢量瓦片,前端按需加载。
Canvas图层覆盖:将点绘制在Canvas上,减少DOM节点。
按需加载:只加载当前视野范围内的点。
Web Worker:将点位的坐标计算放到Worker线程。
你处理过WGS84和GCJ-02(国测局/火星坐标系)的转换吗?高德地图用的是哪种坐标系?如果后端返回的GPS坐标直接打到高德地图上,点位飘移了怎么解决?
参考答案: 高德地图使用GCJ-02坐标系。GPS坐标是WGS84,直接使用会偏移。解决方法是使用转换库(如coordtransform)将WGS84转为GCJ-02再显示。如果后端返回WGS84,前端必须转换;如果后端已转换,直接使用。我曾遇到过GPS轨迹飘移,还使用了卡尔曼滤波进行平滑处理。
Cesium中常用的坐标系有哪些?如何进行坐标转换?
参考答案:
笛卡尔空间直角坐标系(Cartesian3):以地球中心为原点,用于三维空间计算。
地理坐标系(Cartographic):由经度、纬度、高度组成(弧度制)。
屏幕坐标系(Cartesian2):二维屏幕像素坐标。 转换方法:
Cesium.Cartographic.fromDegrees(longitude, latitude, height) 创建地理坐标(度数)。
Cesium.Ellipsoid.WGS84.cartographicToCartesian(cartographic) 转笛卡尔。
Cesium.SceneTransforms.wgs84ToWindowCoordinates(scene, position) 将世界坐标转屏幕坐标。
Cesium中如何加载大规模3D Tiles数据并优化性能?
参考答案:
使用3D Tiles数据格式,支持LOD(细节层次)和流式加载。
设置maximumScreenSpaceError控制屏幕空间误差,平衡加载精度。
使用skipLevelOfDetail和baseScreenSpaceError加速初始加载。
利用剔除机制(视锥剔除、地平线剔除)减少不可见图元渲染。
结合requestRenderMode和maximumRenderTimeChange优化渲染频率。
对模型进行纹理压缩、合并顶点、使用批处理(batch)减少draw call。
---- Python爬虫与数据处理 ----
简历中提到你能破解“瑞数反爬”和“Webpack逆向”。请详细描述破解瑞数反爬的一次经历?是补环境还是扣代码?
参考答案: 以某政务网站的瑞数反爬为例,瑞数主要通过JS动态生成cookie和请求参数。我采用补环境方案:在Node.js中模拟浏览器环境,将瑞数加载的JS代码中检测环境的函数(如navigator、window属性)全部补齐,然后执行生成cookie。同时用AST语法树分析其流程,找到生成参数的核心函数。最终通过Python调用Node执行补环境脚本,获取加密cookie后携带请求,成功绕过。
你提到熟练掌握AES/RSA。请举例说明,在实际爬虫中,你是怎么识别一个接口是AES加密还是RSA加密的?如果遇到动态的RSA公钥,你是如何处理的?
参考答案: 通过抓包分析JS代码:搜索关键词如CryptoJS.AES、mode: CBC/Padding等可识别AES;出现JSEncrypt、setPublicKey等则是RSA。动态RSA公钥通常从服务端获取,我会分析获取公钥的接口,自动提取公钥并在后续请求中动态使用。若公钥加密前还涉及时间戳随机数,需一并模拟。
你写的Python脚本实现“5张基表+4张固定表自动化计算,3张结果表入库”。请描述这个ETL过程的具体逻辑?如何处理脏数据?
参考答案: 逻辑:使用pandas读取基表Excel,进行多表关联、数据清洗(去重、填充空值)、自定义指标计算(如聚合求和),最后生成3张结果表存入PostgreSQL。 脏数据处理:对缺失值用均值或默认值填充;对异常值(如超出范围)记录日志并剔除;对格式不一致的数据(如日期格式)统一转换。同时使用数据库事务,若某条数据插入失败则整体回滚,保证数据一致性。
---- 后端与全栈能力 ----
PostgreSQL(配合PostGIS扩展)相比于MySQL,在存储地理数据时有什么核心优势?你简历中的“基站GIS数据”存入PostgreSQL后,如何用SQL查询某个点周围500米的所有基站?
参考答案: 核心优势:
完整的地理对象支持:点、线、面、几何集合等。丰富的空间函数:距离计算、相交判断、缓冲区分析、投影转换等。空间索引(GIST):高效的空间查询性能。遵循OGC标准,与GIS软件兼容性好。
你提到熟练使用若依框架。请说明若依的前后端交互流程是怎样的?它的代码生成器解决了什么问题?你对若依默认的权限模型做过定制化修改吗?
参考答案: 若依前后端分离版:前端Vue+Element,后端Spring Boot。交互流程:前端请求后端接口,后端通过Shiro/JWT鉴权,返回JSON数据。代码生成器根据数据库表生成前后端CRUD代码,极大提升效率。我定制过权限模型:默认基于RBAC,但项目需要数据权限(如不同部门只能看自己数据),我修改了@DataScope注解,在SQL层面追加部门过滤条件。
你多次提到用Cursor、通义灵码提效。请举个具体例子,说明AI是如何帮你“重构”代码的?你给出的Prompt是什么?AI生成的代码你发现过逻辑错误吗,如何发现的?
参考答案: 例子:重构一个复杂的Vue组件,原本有大量重复逻辑。 Prompt:“将以下组件中的表格分页、搜索、导出功能抽取为可复用的Composition API函数,并保留原有功能。” AI生成了useTable函数,我检查后发现它遗漏了导出参数的传递,手动修正后集成。发现逻辑错误主要靠单元测试和代码审查,AI是辅助,不能完全信任。
---- 场景问题 ----
你提到具备前端组件化/工程化思维。请举例说明,在移动设计院的OMC服务器管理平台中,你是如何设计“可拖拽式多窗口”功能的?状态管理如何设计?为何用sessionStorage保证刷新不丢失,而不是仅用Vuex/Pinia?
参考答案: 我设计了一个窗口管理器组件,每个窗口实例包含id、位置、尺寸、zIndex、内容组件名等元数据。拖拽基于自定义指令和原生鼠标事件实现,位置状态存储在Pinia中,同时通过watch将关键状态(如窗口是否打开)同步到sessionStorage。之所以配合sessionStorage,是因为Pinia是内存存储,刷新会丢失;而sessionStorage可在当前会话恢复窗口状态。但窗口内的具体数据(如表格当前页)不存,只存打开状态和位置,保证刷新后界面恢复但数据重新加载,避免存储过大。
在OMC平台中提到用IndexedDB存储大体积日志并设计缓存清理机制。请详述清理策略?如何避免IndexedDB异步操作带来的数据一致性问题?
参考答案: 清理策略:基于时间戳+最大容量。每条日志存储时记录时间,每次新增前检查总大小,若超过预设阈值(如50MB),则删除最早30%的日志。 数据一致性:使用IndexedDB的事务机制,所有读写操作在同一事务中完成,配合async/await保证顺序执行。增加写入失败的重试机制,若事务失败则回滚并记录错误。
请谈谈你在前端项目中做过哪些性能优化?可以从哪些维度入手?
参考答案:
加载性能优化:路由懒加载、静态资源压缩(WebP、Gzip)、CDN加速、HTTP缓存策略、预加载关键资源。
运行时性能优化:减少重排重绘、虚拟列表、防抖节流、Web Worker处理复杂计算、优化GIS点位渲染(点聚合、Canvas绘制)。
构建打包优化:分析打包体积(rollup-plugin-visualizer)、Tree Shaking、按需加载、SplitChunks拆分公共模块。
GIS专项优化:点位聚合、矢量瓦片、按视野加载、Cesium中设置屏幕空间误差、使用3D Tiles LOD。
AI提效:使用Cursor等工具辅助代码生成,间接保障性能优化落地。
前端常见的安全漏洞有哪些?如何防范?
参考答案:
XSS(跨站脚本攻击):防范措施包括对用户输入进行转义(如innerText代替innerHTML)、使用CSP(内容安全策略)、对Cookie设置HttpOnly。
CSRF(跨站请求伪造):防范措施包括使用Token(如双提交Cookie)、验证Referer、使用SameSite Cookie属性。
点击劫持:通过设置X-Frame-Options响应头或使用CSP的frame-ancestors。
敏感信息泄露:避免在前端硬编码密钥,使用环境变量,HTTPS传输。
点击公司/点位联动刷新数据图表。如果后端返回数据较慢,或者点击后需要聚合多个接口的数据,你在前端如何设计加载状态和错误处理?
参考答案: 设计全局loading状态,每个数据请求独立控制,避免单个接口慢导致整个页面卡死。使用Promise.all或Promise.allSettled并发请求,并展示每个模块的加载骨架屏。错误处理:统一捕获异常,展示错误提示,并提供重试按钮。对于慢接口,可加缓存策略,相同参数短时间内不重复请求。
----- 项目经历深挖(STAR法则) ----
你提到“客户满意度100%”。在面对甲方频繁变更需求时,作为技术负责人,你的需求变更管理流程是怎样的?如何平衡项目交付时间和团队加班? 参考答案: 流程:接到变更需求后,评估影响范围和工作量,与甲方沟通优先级,确定是否纳入本次迭代。若必须纳入,则调整计划,必要时申请延期。若加班不可避免,我会带头攻坚,但事后安排调休或团队建设,保持士气。核心是透明沟通,让甲方理解变更成本,避免无限追加。
---- 针对“专科+32岁+外包”的犀利问题 ----
你的学历是专科,而我们现在这个岗位可能有很多本科甚至研究生投递。你认为你的核心优势是什么,能让我们忽略学历这个门槛?
参考答案: 我理解学历是敲门砖,但多年政企实战证明了我的落地能力。我的核心优势是复合技能+全流程把控:不仅会前端,还能解决数据来源(爬虫)和数据存储(PostGIS),这种“采集-清洗-可视化”闭环能力在政企项目中极为稀缺。另外,我对政企项目规范、交付节奏非常熟悉,能快速理解业务需求,独立完成技术方案设计与核心模块开发,减少沟通成本。实际项目中,解决问题比学历更重要。
32岁对于前端开发来说是一个分水岭。你未来3-5年的职业规划是什么?是想继续写代码,还是想转管理?如何保持技术不被年轻人淘汰?
参考答案: 我计划走技术专家+技术管理双路线。继续深耕GIS+数据可视化领域,同时利用全栈能力成为项目技术负责人。保持学习:持续跟进新技术(如WebGPU、三维实时渲染),通过AI工具提效,并定期输出技术博客巩固知识。年龄不是问题,经验才是财富——我更懂业务、更稳。
你大部分经历都在外包或乙方公司。你认为在乙方做项目和在甲方自研团队做项目,最大的思维差异是什么?你如何看待“外包”标签?
参考答案: 乙方思维是项目导向、快速交付、满足客户;甲方思维是产品导向、长期迭代、用户体验。我在乙方积累了应对多变需求、多团队协作的经验,也理解甲方对稳定性和规范性的要求。外包标签我不避讳,它不代表技术差,反而锻炼了我快速学习和抗压能力。我现在寻求甲方平台,正是想将乙方积累的广度与甲方深度结合。
你工作经历比较丰富,多年换了5-6家公司。如何看待工作的稳定性?这次求职你最看重的是什么?
参考答案: 前几年换工作主要是技术转型和项目调整,最近两份工作持续时间较长(2年、1.5年),说明我趋于稳定。这次求职我最看重业务赛道和技术契合度,希望在一家深耕政企数字化的公司长期发展,将GIS+数据可视化做深做透,成为该领域的专家。
(薪资问题)你之前的薪资是16K,最近一份工作11K(两个月),如果问到薪资该怎么回答?(需查流水,不能隐瞒)
参考答案: (诚实解释+价值锚定) “我上一份正式工作的薪资是16K(税前)。之后因个人职业规划调整,希望深入政企GIS数据可视化领域,加入了一个短期项目(约两个月),由于项目性质是过渡性外包,薪资暂定为11K。但这段经历让我在Python爬虫和PostGIS数据处理上有了更多实战积累,现在完全具备独立解决政企数据获取与可视化难题的能力。目前求职更看重平台和长期发展,期望薪资基于我的经验积累和市场行情,希望能恢复到与之前相当的水平,预期在16K-18K区间。具体可结合公司整体福利协商。”