 zmx2321
zmx23212026年面试题汇总整理
CSS/HTML相关
vue相关
在原理层面上讲vue2和vue3有什么区别
- 对于vue而言,本质上我们可以将它们分成三大模块,响应性reactivity,运行时runtime,编译器compiler,
- 先说响应性,vue2通过Object.definedProperty()去实现响应性,但是这种方法的核心是用来监听指定对象的指定属性的get、set行为,在这种情况下,就会出现一些问题,比如说在vue2的data中声明了一个对象,那么给这个对象在后期某一个时刻去新增属性的时候,因为js本身的限制,我们没办法监听到这个对象新增的这个属性,这个时候,我们就没办法通过Object.definedProperty()去监听对应的新增属性的行为,所以新增的这个属性就不是响应式的了,vue2为了解决这个问题,提供了vue.$set的方法,这个方法本质上就是把这个属性和对象过了一遍Object.definedProperty(),这种方案从程序设计的理念上看,不是很合理, 所以在vue3的时候,他提供了es6新出现的反射和代理的概念,反射指的就是reflect,代理指的就是proxy,他通过proxy来代理了一个复杂的数据类型,通过这样复杂数据类型的代理,我们得到了一个代理对象,就是proxy的实例,然后通过reflect来确定了this上的一个指向,vue3中实现这样的一套流程的方法就是我们常见的raactive,但对于proxy而言,他只能去监听复杂数据类型的响应式,而没办法监听简单数据类型的响应式,比如基本的string和int, 所以vue3里面又提供了ref的方法,ref的方法本质上其实就是把内容分成了两部分,第一部分就是复杂数据类型,在vue内部会直接通过toRective的方法指向reactive, 第二部分的简单数据类型,其实在内部会去处理一个refImpl,也就是ref imploment的一个接口,通过这个接口内部,他实现了两个方法,一个叫做get标记的value,一个叫做set标记的value,通过ref这样的形式,当我们去触发.value这个属性的时候,本质上就是在触发他的value方法,这是响应性上的
- 除此之外还涉及到运行时的runtime的行为,runtime其实大部分指的就是所谓的渲染器也就是render,在这个渲染器对象里面,包含了一个我们常见的渲染函数即render函数,这个render函数内部把宿主环境,也就是所谓的浏览器,或者说是uniapp,uniapp可以使用vue进行渲染的原因,本质上就是因为vue在runtime阶段去进行了一个宿主环境和渲染逻辑的分离
- 第三个就是所谓的编辑器,编辑器我们一般情况下分成三个阶段parse阶段,transform阶段,generate阶段,编辑器本质上就是把template,编辑成为了一个render的函数,在vue3中,他将这个阶段进行了系统的划分,我们可以直接通过baseparse把template直接转化成ast,就是动态抽象语法树,然后利用transfrom把js转化为jsast,就是js标记的抽象语法树,然后再通过generator把jsast拼接成一个render的渲染函数
- 在vue3里面,在项目中要用到的,甚至是一些生命周期,都需要import进行动态导入,这样做的目的是为了更好的 Tree-shaking,因此可以更好地剔除不需要的代码 ●通过main.js可以看出来,vue2整个构造是基于原型链的,vue3主要使用函数去构造的
- vue3中可以没有根标签,实际上他会默认将多个根标签包裹在一个fragement虚拟标签中,有利于减少内存
- Vue 3 的代码库已经全面采用 TypeScript 重写,提供了更好的类型推断和类型提示
- 在vue2中v-for的优先级高于v-if,可以放在一起使用,但是不建议这么做,会带来性能上的浪费,在vue3中v-if的优先级高于v-for,一起使用会报错。可以通过在外部添加一个标签,将v-for移到外层
- diff算法不同,vue2中的diff算法,遍历每一个虚拟节点,进行虚拟节点对比,并返回一个patch对象,用来存储两个节点不同的地方。用patch记录的消息去更新dom
- vue3中的diff算法,在初始化的时候会给每一个虚拟节点添加一个patchFlags,是一种优化的标识。只会比较patchFlags发生变化的节点,进行视图更新。而对于patchFlags没有变化的元素作静态标记,在渲染的时候会直接复用。
- 在使用上,目前使用vue3的话,状态管理从vuex换成了pina,事件总线使用的是mitt
原生js相关
有使用过原生js吗
- 原生js的操作可以分为Dom操作和Bom操作,还有其他一些js api的操作,bom操作,其实就是浏览器相关的操作,比如获取浏览器信息的navigator,获取url信息的location,对浏览器url进行操作的history等
- 对于dom操作的话,主要就是针对html元素的一些增删改查
- 先说dom的新增,比如我们根据http请求,获取并处理好了一些数据,并组成了一段html代码片段,需要将他插入到dom里面的话,可以使用appendChild,但如果我们需要完全替换掉盒子里面的内容的话,可以使用innerHtml,如果我们为了在一个空的盒子里面需要创造一些元素的话,我们可以使用createElement,我们知道,DOM操作比较耗时,我们有时候为了避免频繁的操作dom元素,会对dom进行缓存,就需要使用到dom的代码片段,createDocumentFragment
- 再说说dom的删除,dom的删除其实就是removeChild
- 再说说dom的修改,dom节点的修改实际上就是将innerHtml与appendChild联合起来使用,dom节点上属性的修改,有修改对象属性property,和修改html属性两种,前者不会体现在html中,例如p.style.color,后者会改变html结构,需要使用setAttribute(键值对)、getAttribute
- 最后说一说dom结构的查询,主要就是如何获取dom节点,比如根据id查找,根据类名查找,根据标签名查找,还有就是querySelector、querySelectorAll
- 其他的非dom的原生js操作,有数组操作,xhr的一些操作,正则的一些操作等
js概念相关
浏览器/Http相关
常见的请求头和相应头有哪些
请求头
请求头主要是客户端向服务端发送的请求,主要有:
- Accept => 浏览器可接收的数据格式(text/html、application/json等)
- Accept-Encoding => 浏览器可接收的压缩算法,如gzip
- 我们可以根据gzip算法把资源进行压缩(100kb大概可以压缩至30kb左右)
- 浏览器告诉服务器,我能接收什么样的压缩算法,服务器就会根据Accept-Encoding的压缩算法进行压缩为了保证资源更小,传输地更快一些,前端也可以正常地解压出来
- Accept-Language => 浏览器可接收的语言,如zh-CN
- Connection => keep-alive一次TCP连接重复使用
- 每次请求重新建立TCP连接会很消耗资源,我们和服务端建立了连接之后,就可以重复地使用这个连接,没必要断开之后重连,可以重复地使用一次连接,把资源一次性请求完成,现在的浏览器版本基本上都是支持keep-alive的
- cookie => 同域,每次请求资源的时候都会把cookie带上,浏览器自己带的
- Host => 请求的域名是什么
- User-Agent(简称UA) => 浏览器信息 => 重点
- 能标识你的浏览器信息(类型等)
- 服务端能够接收ua信息,可以判断用户使用的浏览器类型
- Content-type
- 发送数据的格式,如 application/json
- 客户端向服务端请求,要发送一些数据的时候(post),告诉服务端,我们这个数据是什么格式的,一般get请求是没有的,get请求主要是向服务端获取数据
响应头
Content-type => 返回的数据格式
- Content-type => 返回的数据格式
- 如 application/json
- Content-length => 返回数据的大小,多少字节
- Content-Encoding => 返回数据的压缩算法,如gzip
- 客户端告诉服务端支持的压缩算法之后,服务端根据压缩算法进行压缩,服务端压缩之后会通过Content-Encoding告诉客户端我是用什么算法压缩的,浏览器会自动根据这个压缩算法解压
- Set-Cookie
- 服务端改cookie的时候,通过Set-Cookie修改
自定义header
之前说的请求头和响应头是浏览器自带的,或者服务端和浏览器配合加的,但请求头和响应头实际上可以自定义header,自定义请求头的时候,需要前后端进行约定,一般用在简单的权限校验,但不要和浏览器自带的键值冲突
缓存相关的header
- Cache-Control(响应头)、Expires(响应头)、Last-Modified(响应头)、IF-Modified-Since(请求头)、Etag(响应头)、If-None-Match(请求头)
简单介绍一下http的缓存
浏览器访问一个新的网站,服务端会返回所有的资源,并且浏览器或者服务器会将一些不必要重新获取的资源存到缓存区,第二次访问的时候,就不需要全部重新获取一遍资源,有一部分资源会从缓存中获取,即我们可以把一些没有必要重新获取的资源不再重新获取,这就是缓存,http缓存有两种,一种是强制缓存,一种是协商缓存,强制缓存是在有效期内,客户端都不需要经过网络,但协商缓存是每次都要经过网络,但如果命中缓存,即数据没有变化,会返回304,让客户端从缓存获取数据,以下是http的缓存策略的简单介绍:
http的缓存策略主要有两种,强制缓存和协商缓存
强制缓存:
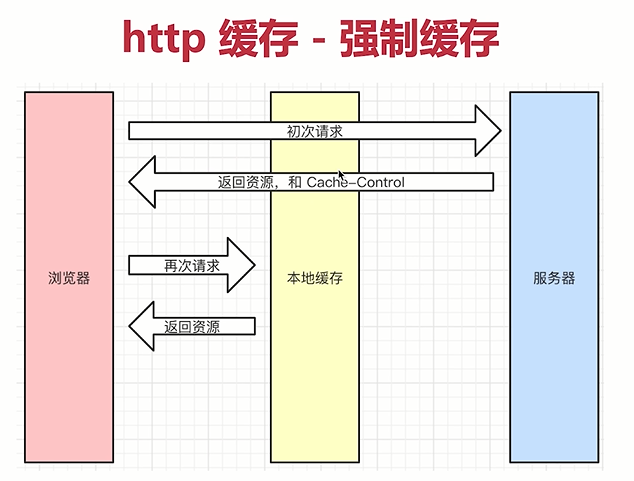
- 当浏览器初次请求到服务器之后,如果服务端感觉这个资源可以被缓存,服务端会返回结果集和一个响应头Cache-Control,如果服务端感觉这个资源不适合被缓存,就不会加上这个响应头,一般些静态资源(js、css、img)都会被加上这个响应头,如果浏览器识别到这个响应头,则会将资源缓存下来
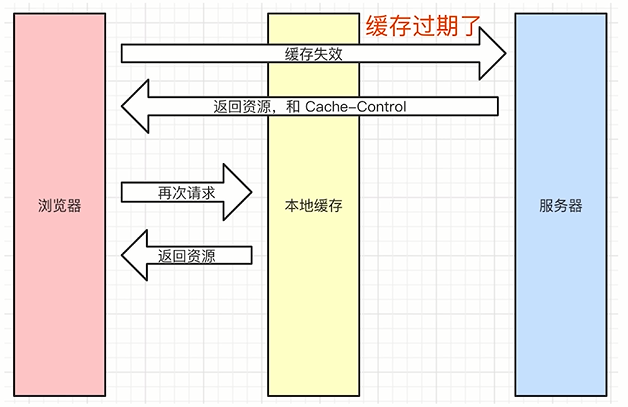
- 当浏览器再次请求的时候,他会在客户端判断Cache-Control这个响应头时间是否过期,如果时间没有过期,浏览器就会在本地缓存中获取资源,直接返回,不会经过经过网 络,如果响应头时间过期了,则继续执行初次请求的步骤
- 服务端控制哪些资源可以加Cache-Control,客户端控制不了,强制缓存本质还是服务端控制的,但在表现上,只要本地的Cache-Control不过期,客户端会先从本地缓存里面找,找到了就判断是否过期
- 强制缓存也可以用Expires来体现,但是因为Expires使用的是绝对时间,如果客户端和服务端的时间不一致,可能会出问题,所以现在一般都使用Cache-Control
协商缓存,也叫对比缓存:
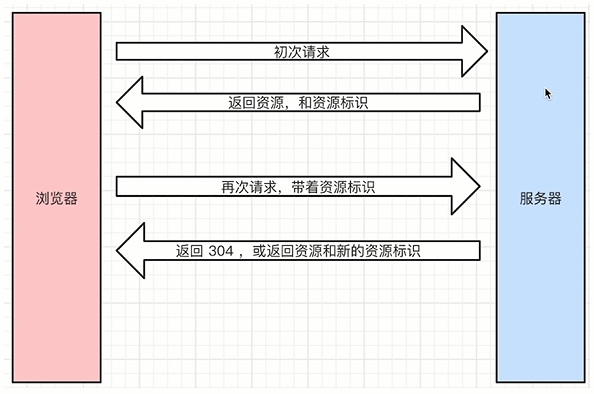
类似一个商量或者沟通的意思,由服务端来判断这个资源是否可以被缓存,我们这个资源到了服务端之后,服务端可以告诉浏览器这个资源没有动,可以直接用本地的缓存就可以了,一般用在客户端资源和服务端资源是一样的,没有被修改的时候,如果判断一致就返回304,否则返回200和最新的资源
浏览器初次请求服务器,服务器返回资源和资源标识,浏览器再次请求,会带着资源标识,服务端根据资源标识判断当前资源是否是服务端最新的资源
Cache-Control这个响应头主要和强制缓存有关,能简单介绍一下这个响应头吗
- max-age => 缓存最大过期时间(秒)
- max-age=31536000 (单位是秒 - 1年)
- 我们需要将某个资源文件在客户端缓存一年的时间,期间都不需要通过网络
- no-cache => 可以在客户端存储资源,但每次都必须去服务端做新鲜度校验
- 使用no-cache的目的就是为了防止从缓存中获取过期的资源
- 设置了该字段需要先和服务端确认返回的资源是否发生了变化,如果资源未发生变化,则直接使用缓存好的资源,即走协商缓存
- no-store(不常用) => 不用强制缓存,也不让服务端做缓存,让服务端直接返回资源
- private => 只能允许最终用户做缓存(设备)
- 设置了该字段值的资源只能被用户浏览器缓存,不允许任何代理服务器缓存。在实际开发当中,对于一些含有用户信息的HTML,通常都要设置这个字段值,避免代理服务器(CDN)缓存
- public(不常用) => 中间的代理也可以做缓存
- 设置了该字段值的资源表示可以被任何对象缓存
- 延伸:关于Expires
- 经常会和Cache-Control并列在一起,同样在响应头中,同为控制缓存过期,但已经被Cache-Control代替,现在的浏览器兼容这两种写法,如果同时存在,以Cache-Control为主
- Expires标识缓存到期时间,是一个绝对时间,如果客户端从他的缓存的这个字段里面找到这个时间,发现这个时间过期了,那就会发起网络请求去获取数据。
- 但是他的缺点也很明显,由于这个时间是绝对时间,那我客户端修改了本地时间,这个缓存不就失效了嘛。
- 为了解决Expires的问题,才引入了Cache-Control。Cache-Control代表了缓存的有效期,是一个相对时间,不管你客户端本地时间是什么,我只会返回给你一个有效期,相当于倒计时,只要这个倒计时到零了,你就给去获取缓存了。
简单介绍一下协商缓存的资源标识
- 在响应头中,协商缓存的资源标识主要有两种,Last-Modified和Etag
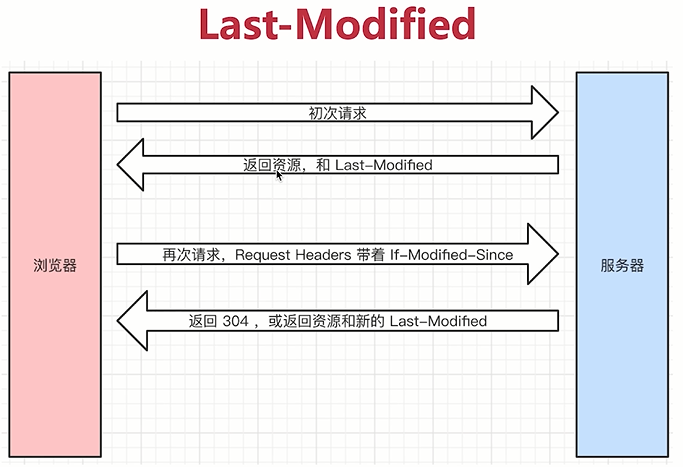
- Last-Modified => 值时资源的最后修改时间
- 浏览器第一次请求的时候,服务端返回资源和Last-modified,值是最后修改时间,浏览器再次请求的时候,请求头会带着If-Modified-Since,If-Modified-Since是Last-Modified的key,值也是最后修改时间,即前端请求的和后端返回的资源标识名字不一样,但值是一样的,url就可以代表这个资源,判断这个资源的最后修改时间是不是和带来的这个If-Modified-Since值是一样的,服务端会判断If-Modified-Since和Last-modified是否相等,这两个值相等,就返回304,服务端修改的话,会改变Last-Modified的值,服务端每返回一个Last-Modified,If-Modified-Since的值就会修改,服务端根据带来的时间和资源的最后修改时间做一个协商,做一个对比,看看能不能返回304,新的Last-Modified力求下次能命中缓存
- Last-Modified => 值时资源的最后修改时间
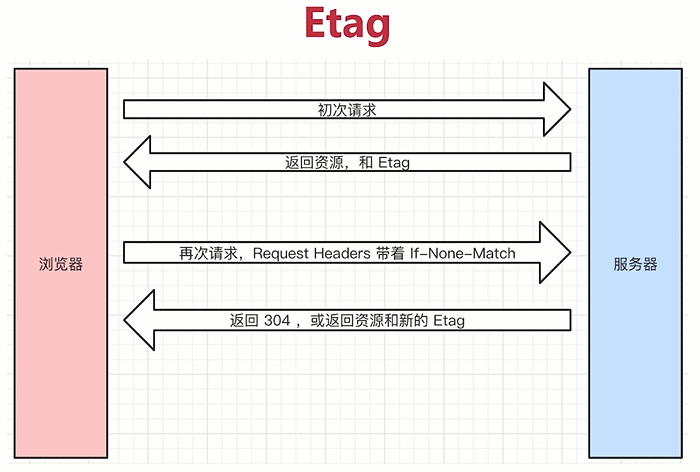
- Etag => 资源的唯一标识(值时一个唯一的字符串,类似人类的指纹)
- 服务端返回资源和Etag(就是一个字符串),但是要保证唯一性
- 浏览器发现有Etag之后,就会把资源缓存下来,把Etag也记下来
- 浏览器再次请求,请求头带着If-None-Match
- 再次请求的时候请求头会带上If-None-Match,他的值实际上就是Etag
- 服务端发现有If-None-Match之后,服务端就会根据当前资源重新计算一个Etag,再和If-None-Match的值进行对比
- 比如一些静态资源,比如webpack打包的时候,我们会加一个hash,hash是通过资源内容来算的,打包之后的静态资源文件,加上hash后缀之后,资源是不会被修改的,如果内容改了之后,会生成一个新的hash的名称
- 如果这个资源没有变过,算出来的Etag应该和If-None-Match的值是一样的,就会返回304
- 如果对比值不一样,就会返回一个新的Etag和新的资源
- Last-Modified和Etag的注意事项
- 会优先使用Etag,因为Last-Modified只能精确到秒级,秒对计算机而言,是一个比较大的单位,以程序而言,一般是以毫秒为单位
- 如果资源被重复生成,而内容不变,则Etag更精确,如果资源1s生成一次,内容不变,Last-Modified每次都会过期,重新返回新资源
- Etag他是根据内容计算的(类似webpack的hash),内容不变,就算1s重新生成一次,他的Etag值也不会变化
列举出浏览器缓存的所有情况
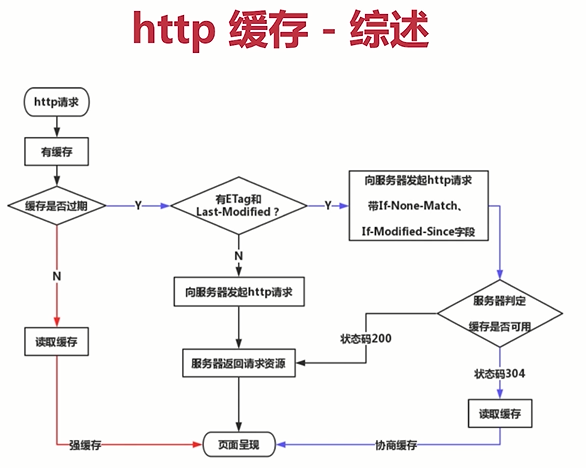
- 根据图示梳理缓存流程
- 第一种情况
- 发送http请求
- 如果有缓存
- 判断缓存是否过期
- Cache-Control里面有个max-age,即最大缓存时间
- 如果没有过期
- 读取缓存 => 强缓存
- 页面呈现
- 第二种情况
- 发送http请求
- 如果有缓存
- 如果缓存过期
- 判断有没有Etag或Last-Modified
- 可以同时存在
- 如果没有,就直接向服务器发起http请求
- 服务器返回请求资源
- 页面呈现
- 第三种情况
- 发送http请求
- 如果有缓存
- 如果缓存过期
- 判断有没有Etag或Last-Modified
- 如果有则向服务器发起http请求,并且带上If-None-Match或If-Modified-Since字段
- 可以同时存在
- 服务器判断缓存是否可用
- 如果不可用,直接请求服务器资源,返回200
- 页面呈现
- 第四种情况
- 发送http请求
- 如果有缓存
- 如果缓存过期
- 判断有没有Etag或Last-Modified
- 如果有则向服务器发起http请求,并且带上If-None-Match或If-Modified-Since字段
- 服务器判断缓存是否可用
- 如果缓存可用,返回状态码304
- 读取缓存(协商缓存)
- 页面呈现
- 第一种情况
不同刷新操作,不同的缓存策略
- 正常操作:强制缓存有效,协商缓存有效
- 对大部分用户都有效
- 手动刷新:强制缓存失效,协商缓存有效
- 如果所用的操作都可以命中强制缓存,协商缓存就没有用了
- 强制缓存判断在客户端
- 协商缓存判断在服务端
- 只有协商缓存也会让页面加载地更快一些
- 强制刷新,强制缓存失效,协商缓存失效
- 不管多慢,都要全部返回最新的资源
从浏览器输入到页面展示做了什么
- 在用户输入到展示的几秒钟里面,浏览器会经历一系列复杂步骤将网页内容呈现在屏幕上
- 计算机主要做了两个事情,一个是加载资源,一个是渲染页面
- 同时总体可以分为四个大步骤
- DNS解析 => TCP连接 => HTTP请求 => 渲染页面
DNS解析
- 刚开始浏览器会对输入的url进行解析,提取出协议,主机名,路径等信息,这里面涉及到http和https的一些概念,如果是https的话,为了安全,会去做一些处理
- 接下来浏览器会将主机名转换成对应的ip,这个过程被称之为dns解析
- 浏览器会首先检查本地的dns缓存,如果有匹配的ip直接进行访问,如果没有的话,会向dns服务器发送请求,来获取对应的IP地址
TCP连接
- 转换成ip之后,浏览器会通过ip地址和端口号来与服务器建立tcp链接,这个过程是通过tcp的三次握手完成的,以确保双方可以正常通信
- 第一次握手,客户端发送syn包到服务器,并且客户端进行syn_send状态,等待服务器确认
- 第二次握手,服务器接收到syn包时,会发送一个syn+ack包给客户端,服务器进入syn_recv状态
- 第三次握手,客户端接收到syn+ack包之后,向服务器发送确认ack的包,至此三次握手结束
- 简易记法
- 发送方(计算机A)先传达一个连接意愿 => 在吗,来一把?
- 接收方(计算机C)收到连接意愿后,回复一个连接确认,表示同意连接 => 在,来吗
- 发送方(计算机A)收到连接确认后,再次发送一个连接确认,表示连接成功 => 来了,来了
HTTP请求
- 建立tcp连接之后,客户端与服务器就开始传输数据了
- 首先浏览器会向服务器发送http请求,请求的内容包括方法,请求头部,和请求体等
- 如果是get请求,请求体在url上
- 请求头包括浏览器自带的请求头和自定义的请求头,自定义的请求头可以用于登陆等场景
- 浏览器自带的请求头包括浏览器的一些信息,浏览器可接收的压缩算法,浏览器可接收的数据格式,content-type,accept等等
- 服务器接收到浏览器发送的请求之后,会进行处理,包括读取数据库,处理一些业务逻辑,生成一些动态内容等
- 服务器处理完请求,会对处理结果封装成http响应,包括状态码,响应头部,响应体等
- 浏览器自带的响应头也包含content-type,除此之外还有返回数据的压缩算法格式等,服务器修改cookie时,通过set-cookie修改
- 浏览器接收到服务器的响应后,会对这个响应进行解析,如果响应体是html文档,则会下载其中引用的其他资源,例如js,css,静态文件等
- 响应结束之后,为了更彻底地释放双方的资源,引入了四次挥手
- 四次挥手的时间,看是否设置了keep alive属性
- 第一次挥手,客户端发送终止请求报文段
- 第二次挥手,服务器接收到请求并发送确认报文
- 第三次挥手,客户端收到确认并发送确认报文
- 第四次挥手,服务器接收到确认报文并终止连接
- 简易记法
- 发送方(计算机A)先传达一个关闭意愿 => 要不退了吧
- 接收方(计算机C)收到关闭意愿后,回复一个关闭确认,表示同意关闭 => 行,等我这把刷完
- 接收方(计算机C)数据处理完毕,再向计算机A传达一个关闭意愿 => 刷完了,你可以退了
- 发送方(计算机A)收到关闭确认后,再次发送一个关闭确认,表示关闭成功 => 你也退吧,下次别再打野了
- 四次挥手的时间,看是否设置了keep alive属性
- 在请求和响应的过程中,中间还有一个很重要的步骤,就是浏览器的缓存
- 浏览器的缓存主要包括强制缓存和协商缓存,强制缓存的判断主要在客户端,协商缓存的判断主要在服务端
- 强制缓存主要使用cache-control,浏览器初次请求到服务器时,服务器不止返回资源,还会返回一个cache-control,客户端如果看到有这个标识,会将资源缓存下来,后面请求的时候会看这个标识是否过期,不过期的话就不进行请求
- 协商缓存主要使用last-modified和etag进行标识,服务端会对客户端请求的资源进行判断,如果请求的资源时一样的,就会返回304,否则就会返回200
- http缓存不一定只用一种方式,经常会一起使用,这时候就要了解两种缓存的执行流程
- 发送http请求,一般来说,首先是判断是否命中强制缓存,再判断是否命中协商缓存,如果有强制缓存,但缓存过期,就会进入协商缓存的过程,如果服务端判断缓存不可用,即没有last-modified和etag标识或者标识不一致,就不会命中协商缓存,手动刷新的时候,协商缓存还是有效的,只有强制刷新,才能使两个缓存都失效
渲染页面
渲染流程的简单回答
- 解析下载完资源之后,浏览器会将html解析器解析成dom树,然后使用css解析器将css文件解析成样式规则,接着,浏览器根据dom树和样式规则进行渲染,将页面内容显示在浏览器上
- 浏览器根据html代码生成文档对象模型树(DOM Tree),浏览器根据css代码生成css对象模型(cssOM),再将文档对象模型树和css对象模型整合形成渲染树(Render Tree),浏览器根据渲染树渲染页面,如果遇到
<script>则暂停渲染,优先加载并执行JS代码,完成再继续,js和渲染是共用一个线程的,因为js有可能会改变渲染树结构,当JS代码执行完之后,再继续进行渲染,直到渲染树渲染完成
渲染流程的完整回答
- 以上只是浏览器渲染页面的简单描述,实际上,浏览器在渲染页面这一步做的步骤非常多,要了解其中的步骤,首先需要了解浏览器的进程模型
- 我们知道软件的运行时需要开启进程的,浏览器也是,浏览器是一款多进程多线程的应用程序,浏览器的内部工作极其复杂,复杂程度已经堪比一个操作系统了
- 当浏览器启动之后,它会自动启动多个进程,每个进程都有独立的内存空间,进程之间相互独立,互不干扰,浏览器启动的进程主要有以下几种
- 浏览器进程
- 主要用来做界面展示,用户交互,子进程管理,同时浏览器进程内部会启用多个线程处理不同的任务
- 渲染进程(我们需要了解的重点)
- 浏览器启动之后,会自动打开一个标签页,这个标签页就是一个渲染进程,即一个标签页一个渲染进程
- 网络进程,等等……
- 浏览器进程
- 渲染进程启动后,会开启一个渲染主线程,渲染主线程是浏览器中最繁忙的线程,它会执行HTML解析、CSS解析、JavaScript执行、布局(宽高位置)、绘制等任务
- 同时因为所有渲染任务都是由渲染主线程完成的,所以如果渲染主线程被阻塞了,那么页面就会卡顿,为了解决这个问题,引入了排队的概念,即我们所说的时间轮询
- window.onload和DOMContentLoaded的区别是什么
- window.onload是页面的全部资源加载完才会执行,包括图片、视频等
- DOMContentLoaded是DOM 渲染完即可执行(网页加载完了),此时图片、视频还可能没有加载完
综合相关
在开发中遇到的最大问题是什么
- 考核你解决项目问题的能力
- avue项目
- 之前有家公司做项目用的avue,avue里面的api比较简单,也有些bug
- avue主要是element-ui的集成,主要是针对一些简单的表格的,他的筛选、表格、分页都是写在一起的
- 但对于复杂的表格,比如一个tab页里面有两个表格全是前端维护的,表格里面有按钮,按钮点进去会触发另一个表格,表格里面还有文本框下拉框以及还有各种校验,一个下拉菜单有很多限制,触发一个下拉菜单会对表格文本框做一些禁用或者显示隐藏,点击提交会在父表格增加一条记录同时影响另外的表格,这种avue坑就有很多
- git方面有
- 由于我有段时间有管理团队,团队开发用的是git,我那时候git基本都可以用,但分支这块用的不熟,所以找时间把分支系统了解了一下
- 还有就是我的博客用的是github page,但现在github使用https上传很麻烦,会经常push不上去,捣鼓了很久,用ssh上传解决了
- 还有的就是我的博客,vuepress里面加上评论和阅读量找了一些插件
- 部署项目
- 做管理的那段时间,领导要求我去部署前后端项目,在安装nginx的时候出了点问题,导致他不能访问,后来排查出来时防火墙的问题
- 在客户端部署nginx服务的时候,有时候因为vue项目里面的接口是走代理的,nginx也要配置相应的代理
- 服务器上有些东西需要加密,可以在nginx上配置密码
- 部署三维模型的时候,模型和项目是分开部署的,都是在nginx里面,模型的请求一直出现跨域,后来配置了nginx-cros才解决问题
- 新东西
- 之前公司在做数据中台的时候需要用elk
- 使用es存储数据最大的问题是es如何与前端框架结合,我后来使用proxy代理的方法,然后在某个js里面封装es增删改查语法,才在项目里用起来
- 用node做爬虫的时候,由于有很多反爬虫机制,后来我用nightmare这个库来模拟浏览器操作,才解决了问题
- 剩下的就是模型上的一些问题了
- 更多的是模型数据上的处理以及模型如何与硬件设备一一对应
- 最大的问题是模型数据如何在场景里面去使用,后面了解到3dtiles,后面慢慢摸索,可以把各种类型的像dae、obj、oggb、bim转换成3dtiles,并在页面中渲染
- 3维场景里面的最大问题是浏览器崩溃和锯齿,通过了解一系列cesium配置,可以把影响降低到最小
- 在业务场景中有的不是点击标注做的交互,要直接点击模型,后面了解到模型的单体化,和数据进行沟通交流,才把问题解决
- 更多的是模型数据上的处理以及模型如何与硬件设备一一对应
- 最后是项目管理的一些坑
- 其实也不能说是坑,项目把控的时候要做excel表格,主要是我那时候不熟悉,后面excel熟练了一些
- avue项目